1. Abstract
Understanding Rhyme Through Network Analysis
Rhyme enacts numerous relationships in poetic texts: relationships between words that share similar sounds; relationships between lines of verse that end in rhyming words; and relationships between the sound and semantic meaning of words that are linked together through rhyme. This panel brings together different approaches to using network analysis to understand the relationships that rhyme enacts in poetry in different language traditions. As the papers in this panel suggest, as one moves from considering rhyme’s function within a single poem to examining larger datasets, one can also consider how rhyme connects words, documents, and/or authors within a corpus.
By juxtaposing papers focusing on poetry in Czech, English, Russian, and Spanish, this panel highlights the fact that rhyme is defined differently in different linguistic and poetic contexts, due to the levels of inflection present in different languages and to the development of different poetic traditions. Some rhyme definitions focus on the shared stressed vowel of single syllables, others encompass polysyllabic rhyme, and others focus on component phonemes, rather than whole words. Thus computational approaches to rhyme must be tailored to the particular languages of the texts under study.
The papers on this panel use different network analysis and graph visualization methods to examine rhyme at the level of the corpus or dataset, rather than the individual poem, in order to understand how rhyme practice changes over time, across languages, and in relation to literary canon formation. It thus contributes both to computational poetics and distant reading methodologies within the digital humanities.
Distant Reading Nineteenth-Century British Poetry With Rhyme Networks
Natalie M. Houston
University of Massachusetts Lowell
1. Introduction
The expectations and assumptions that nineteenth-century English readers brought to their reading of poetry was necessarily different from that which readers today bring to the same texts. One feature of that historical difference was their familiarity with poetic rhyme, and the assumptions about poetic language that it created. By examining rhyme words and sounds in a large dataset of English poems, we can better understand how rhyme shaped poetic discourse in the nineteenth century. This paper suggests that network analysis methods are useful for understanding the semantic networks created by the relatively limited set of rhymes available in English; for examining chronological and aesthetic explanations for changes in rhyme practice; and for exploring the relationships between poems that use the same rhyme pairs. Such analyses reveal the semantic and sonic features of conventional nineteenth-century poetry, and can thereby also distinguish unconventional or distinctive uses of rhyme.
2. Context
The vast majority of English poems published in the nineteenth century were rhymed (95% of the 108,842 poems in the Chadwyck-Healey English Poetry corpus used for this study). Both poets and readers thus expected poetry to be rhymed (McDonald 2012, 7) and many of the rhyme sounds and rhyme words used in nineteenth-century poetry were so frequently used as to create a set of implicit conventions of poetic discourse. Uncovering such implicit conventions can help reveal the structures of the field of poetry at the large scale (Bourdieu 1993).
3. Method
This project identifies rhyme words, groups, and syllables through a method that operationalizes the historical rules for rhyme found in nineteenth-century British rhyme dictionaries, in order to match words according to historical pronunciation and poetics (Houston 2016, 2019). Three different kinds of network analyses are then performed: a rhyme word co-occurrence network, a rhyme pair co-printing network, and a textual coupling network (Houston 2017).
4. Rhyme
Networks
Because rhyme word frequency in British poetry follows a power law distribution, in which a small number of rhyme words are very frequently used, followed by a long tail of additional words, the rhyme word co-occurrence network can reveal the relationship between those frequencies and the clusters of rhyme words that are most likely to occur within the same poem. The rhyme pair co-printing network, based on co-citation analysis, links specific rhyme pairs if they appear in the same poem. Together these two networks reveal the semantic and sonic patterns that structured nineteenth-century poetic discourse. The textual coupling network, based on bibliographic coupling, links two poems if they use the same rhyme pairs. This network reveals chronological and aesthetic subgroups, suggesting how rhyme practice changed through the century.
Bourdieu, P. (1993). “The Field of Cultural Production, or: The Economic World Reversed.” In The Field of Cultural Production: Essays on Art and Literature. Ed. Randal Johnson. New York: Columbia University Press. 29-73.
Houston, N. (2019). “An Evaluation of Rhyme Detection Using Historical Dictionaries.” Digital Humanities 2019, Utrecht University, Netherlands.
Houston, N. (2016). “Exploring the Rules of Rhyme: Operationalizing Historical Poetics.” Digital Humanities 2016, Krakow, Poland.
Houston, N. (2017). “Measuring Canonicity: a Network Analysis Approach to Poetry Anthologies.” Digital Humanities 2017, McGill University, Montreal Canada.
Jauss, H.R. (1970). “Literary History as a Challenge to Literary Theory.” Trans. Elizabeth Benzinger. New Literary History 2.1: 7-37.
McDonald, P. (2012). Sound Intentions: the Workings of Rhyme in Nineteenth-Century Poetry. Oxford: Oxford University Press.
Recurrences of rhymes in 19th century Czech poetry as compared to English, German, Spanish, and Russian
Petr Plecháč
Institute of Czech Literature, Czech Academy of Sciences
As one may expect, we find that in all the languages examined the tendency to share rhyme pairs is stronger between works that come roughly from the same period than between those distant in time. We thus try to represent each work as a vector defined by the relative frequencies of rhyme pairs and use machine learning techniques (Random Forest, Support Vector Machine) in order to classify them into time periods or poetic movements. Cross-validations of the models show that depending on what classes are being used, the accuracy varies between 0.6 to 0.9 and always outperforms the random baseline.
The datasets come from:
- The Corpus of Czech Verse (Plecháč, P. – Kolár, R. 2015)
- The Gutenberg English Poetry Corpus (Jacobs 2018)
- Metricalizer corpus of German poetry (Bobenhausen–Hammerich 2015),
- Corpus of Spanish Golden-Age Sonnets (Navarro-Colorado 2017) & Diachronic Spanish Sonnet Corpus (Ruiz Fabo et al. 2017)
- Russian National Corpus (http://www.rusropora.ru)
References
Bobenhausen, K. – Hammerich, B. (2015). Métrique littéraire, métrique linguistique et métrique algorithmique de l'allemand mises en jeu dans le programme Metricalizer. Langages 199, 67–87.Jacobs, A. M. (2018). The Gutenberg English Poetry Corpus: Exemplary quantitative narrative analyses. Frontiers in Digital Humanities 5:5.
Navarro-Colorado, B. (2017). A metrical scansion system for fixed-metre Spanish poetry. Digital Scholarship in the Humanities 33(1), 112–127.
Plecháč, P. – Kolár, R. (2015). The Corpus of Czech Verse. Studia Metrica et Poetica 2(1), 107–118.
Plecháč, P. (2018). A collocation-driven method of discovering rhymes (in Czech, English, and French poetry). In M. Fidler – V. Cvrček (eds.), Taming the Corpus. From Inflection and Lexis to Interpretation. Cham: Springer, 79–95.
Reddy, S. – Knight, K. (2011). Unsupervised discovery of rhyme schemes. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics. ACL, Portland, 77–82.
Ruiz Fabo, P. – Bermúdez Sabel, H. – Martínez Cantón, C. – Calvo Tello, J. (2017). Diachronic Spanish Sonnet Corpus (DISCO). Madrid, UNED. https://zenodo.org/record/1069844
Network analysis and Russian rhyme
David J. Birnbaum
Elise Thorsen
Conventions about the nature of phonetic similarity in Russian rhyme have varied over time. At the end of the explosively innovative “Silver age of Russian literature”, Viktor Žirmunskij (1923) and Valerij Brjusov (1923) both recognized a prevailing tendency in poetic composition of the time to test the limits of rhyme, but with subtle differences: either as a shedding of an artificial apparatus to the bare essentials of rhyme or as an elaboration on the rule set defining the rhyme zone. Žirmunskij’s and Brjusov’s approaches to rhyme were formal, but not quantitative, nor, of course, computational. Mixail Gasparov (1984) later argued that rhyme is often contingent on outside conditions, including prosodic innovations of one era becoming marked archaisms to avoid in another. Gasparov’s approach was explicitly quantitative, although also not computational. As in other dimensions of his quantitative studies of poetry, Gasparov produced a well-defined set of categories describing common deviations from exact phonetic repetition, and his pioneering work informs our computational exploration of imperfect end-rhyme.
Rhyme studies often operate at a corpus level, constructing large sets of rhyme pairs or nests that serve as training material for supervised machine-learning approaches to recognizing rhyme (see, for example, Plechá? 2018). This type of approach yields structured data that can be used for varied explorations of rhyme in verse, including network visualization, but a force-directed graph of word rhyme in a large corpus quickly becomes illegibly cluttered. Perhaps more importantly, where the object of study is the fluidity of rhyme over time, as is the case for us, an inventory of rhymes over a large corpus elides the instability and contingency of rhyming practice. Network graphs of word rhyme in individual poems (e.g., Lombardi 2013) are well suited to the visualization of rhyme, including imperfect rhyme, within a coherent domain, but because the number of rhyming words in a single poem is small, it is difficult to compare the network graphs of poems in a way that benefits meaningfully from network visualization.
Our approach to rhyme, and especially our focus on the fluid conventions of imperfect rhyme, relies on structural levels smaller than the word, such as phonetic segments and phonetic distinctive features (Birnbaum and Thorsen 2017, 2018, and 2019), and these close perspectives can be seen as complementing word-level approaches to rhyme. Segments and distinctive features lack lexical semantics, and therefore do not provide access to the types of meaning that are encoded or created by rhyme associations. But because the inventory of segments and distinctive features is (compared to lists of rhyming words) relatively small and relatively stable, they create a means of profiling rhyme that can be visualized with less clutter than network graphs of words, and that can be compared more easily. Our contribution to this panel, then, explores the opportunity for the graphic visualization of network rhyme relations below the word level and in the context of the mutability of rhyme conventions over the history of Russian verse.
Works cited
Birnbaum, David J. and Elise Thorsen. 2017. “Exploring inexact rhyme in Russian verse.” Presented at “Plotting poetry | Machiner la poésie”, 5–7 October 2017, Universität Basel.
Birnbaum, David J. and Elise Thorsen. 2018. “The automatic detection of Russian rhyme.” Presented at “Plotting poetry 2: bringing deep learning to computational poetry analysis”, 12–14 September 2018, Freie Universität Berlin.
Birnbaum, David J. and Elise Thorsen. 2019. “Rules-based and machine-learning approaches to identifying Russian rhyme.” Presented at “Plotting poetry (and poetics) 3”, 26–27 September 2019, ATILF, Nancy.
Brjusov, Valerij Jakovlevi?. 1923. “O rifme.” Review of: Viktor Maksimovi? Žirmunskij, Rifma, ee istorija i teorija. Voprosy poètiki (Rossijskij institut istorii iskusstv), vyp. 2. Petrograd: Academia.
Gasparov, Mixail Leonovi?. 1984. O?erk istorii russkogo stixa. Metrika, ritmika, rifma, strofika. Moscow: Nauka.
Lombardi, Thomas. 2013. “Network models of rhyme: ‘The raven’.” https://telombardi.wordpress.com/2013/08/08/network-models-of-rhyme-the-raven/
Plechá?, Petr. 2018. “A collocation-driven method of discovering rhymes (in Czech, English, and French poetry).” In M. Fidler, V. Cvr?ek, eds., Taming the corpus. From inflection and lexis to interpretation. Cham: Springer, 79–95.
Žirmunskij, Viktor Maksimovi?. 1923. Rifma—ee istorija i teorija. Petrograd.
Rhyme network analysis in a non-canonical corpus of sonnets in Spanish
Pablo Ruiz and Helena Bermúdez
Rhyme constitutes a structural element for specific poetic forms, like sonnets. Given its relevance in versification, computational studies of rhyme can provide insight about style and intertextuality. We propose an exploration based on network analysis. Seeking representativity, we analyzed a corpus that draws from online anthologies, including non-canonical authors. We discuss challenges involved with this material and how networks can help analyze it.
Previous work employing network analysis of rhyme includes Houston (2017) for Victorian poetry, List (2016) for Old Chinese, Osinova (2016) for Russian, or Sonderegger (2011) for English poetry ca. 1900. Network nodes in these works are mainly rhyme-words, with edges indicating rhyme-pairs. Our contribution here is creating author networks, where rhyme-pairs are the edges between authors, which can be exploited to assess intertextuality between specific authors.
We analyzed the DISCO dataset of sonnets in Spanish (Ruiz et al., 2018), which contains rhyme annotations, besides author metadata for birthplace and period. The corpus sources are online sonnet anthologies (García, 2005; 2006a; 2006b) which cover lesser-known authors besides some canonical ones, from Spain and Latin America, between the 15th and the 19th centuries. The corpus can be found at https://github.com/pruizf/disco/tree/v3
Considerable rhyme-pair recurrence across authors was attested. We first discuss findings regarding central authors in the network, then some peripheral authors, and finally how peripheral patterns revealed textual errors in the corpus.
The most central author (Fig. 1) is 16th-century Spanish author Juan de Arguijo, patron of a canonical author, Lope de Vega (Asensio, 1883: 26). Arguijo’s centrality is not surprising; early scholars already noted that he had contemporary followers like Rodrigo Caro (Colon i Colon, 1841: 9). While not surprising, Arguijo’s position can be seen as an indication of the network’s sanity.
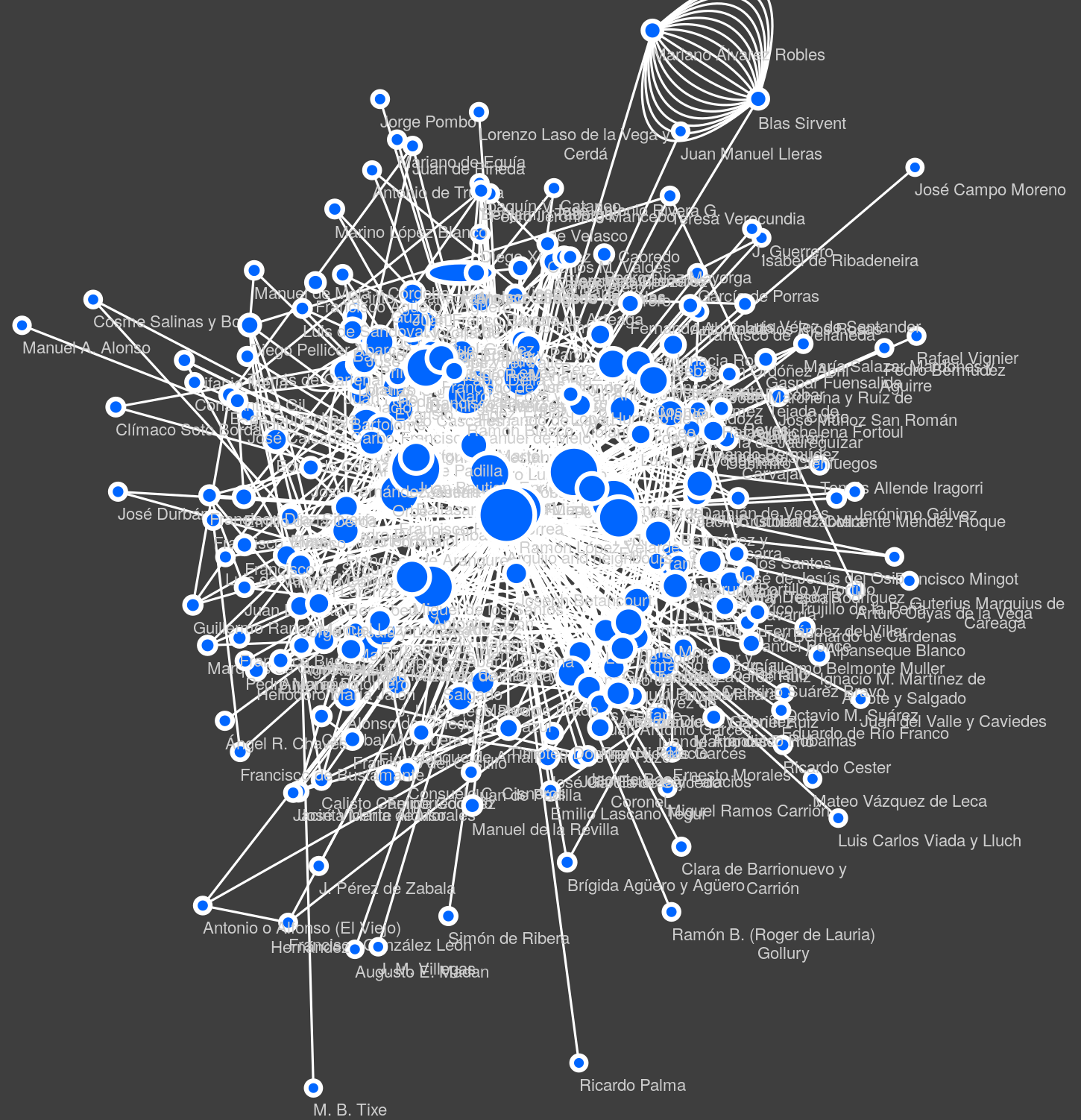
Figure 1. Most central author, Juan de Arguijo, and first neighbours grouped together (central node)
Peripheral areas of the network may also show interesting facts. In the top-right area of Fig. 1, two little-known authors strongly connected to each other appear. From discussions in López Cruces (2000: notes 95-96), we deduce that both wrote for a periodical that challenged authors to create sonnets using pre-established unlikely rhyme-words; the network seems to reflect this.
To explore rhyme richness, a bipartite network with authors and rhyme-pairs as nodes was created. Non-central areas of this second network revealed data problems. Several disconnected components appeared (Fig. 3). These correspond to poems anthologized twice, but under two different author name variants The transmission of peripheral literature, via non-canonical sources, can pose “noise” problems. Finding these errors via networks highlights how they can help data curation: eccentricities led us to a close reading of some of the authors, then spotting textual problems.
In summary, the paper shows how networks based on a heterogeneous, largely non-canonical corpus can confirm trends in it, besides showing interesting peripheral patterns and helping address textual problems inherent to the transmission of lesser-known literature. Future work includes integrating rhyme-data from a canonical sonnet corpus (Navarro-Colorado et al., 2016), for comparison. Also, evaluating rhyme variety per author considering the commonness of rhymes in different subnetworks, to assess originality vs. variety.
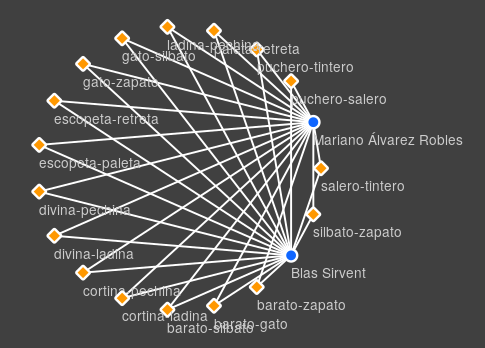
Figure 2. The bipartite network, filtered to isolate two strongly connected authors, also seen at the top-right of the author network on Fig. 1. Both authors (round nodes) share unusual rhymes (diamond nodes); from the literature we deduce they took part in a writing challenge involving those rhyme-pairs

Figure 3. Disconnected components revealed textual problems in the dataset’s sources
References
Asensio, J. M. (1883). Don Juan de Arguijo. Estudio biográfico. Madrid: Tipografía Guerrero. https://archive.org/details/AFol0681588/ (Accessed 13 Oct. 2019)Colon i Colon, J. (1841). “Introducción”. Sonetos de Don Juan de Arguijo. Sevilla: Francisco Álvarez. https://archive.org/details/AMont14417/ (Accessed 13 Oct. 2019)
García González, R. (2005). Sonetos del siglo XVIII. Biblioteca Virtual Miguel de Cervantes, http://www.cervantesvirtual.com/obra-visor/sonetos-del-siglo-xviii--0/html/. (Accessed 13 Oct. 2019)
García González, R. (2006a). Sonetos del siglo XV al XVII. Biblioteca Virtual Miguel de Cervantes, http://www.cervantesvirtual.com/obra-visor/sonetosdel-siglo-xv-al-xvii--0/html/ (Accessed 13 Oct. 2019).
García González, R. (2006b). Sonetos del siglo XIX. Biblioteca Virtual Miguel de Cervantes, http://www.cervantesvirtual.com/obra-visor/sonetos-del-siglo-xix--0/html/ (Accessed 13 Oct. 2019).
Houston, N. (2017) Measuring Canonicity: a Network Analysis Approach to Poetry Anthologies. In Digital Humanities 2017. McGill University, Montreal Canada, pp. 476-478
List, J. (2016). Using Network Models to Analyze Old Chinese Rhyme Data, Bulletin of Chinese Linguistics, 9(2), 218-241. doi: https://doi.org/10.1163/2405478X-00902004
López Cruces (ed.) (2000). Poesías jocosas, humorísticas y festivas del siglo XIX. Alicante: Biblioteca Virtual Miguel de Cervantes (Digital edition based on 1992 print edition from Alcodre, Alicante). http://www.cervantesvirtual.com/obra-visor/poesias-jocosas-humoristicas-y-festivas-del-siglo-xix--0/html/ (Accessed 13 Oct. 2019)
Navarro-Colorado, Borja, María Ribes Lafoz and Noelia Sánchez (2016): Metrical Annotation of a Large Corpus of Spanish Sonnets: Representation, Scansion and Evaluation, in Proceedings of the Language Resources and Evaluation Conference. http://www.lrec-conf.org/proceedings/lrec2016/pdf/453_Paper.pdf (Accessed 14 Oct. 2019)
Ruiz, P., Bermúdez, H., Martínez, C. I., González-Blanco, E., & Navarro-Colorado, B. (2018). The Diachronic Spanish Sonnet Corpus (DISCO): TEI and Linked Open Data Encoding, Data Distribution and Metrical Findings. In Digital Humanities 2018: Conference Abstracts. Red de Humanidades Digitales, Mexico City, pp. 486-489. http://e-spacio.uned.es/fez/eserv/bibliuned:363-Pruiz3/Ruiz_Fabo_Pablo_DISCO.pdf (Accessed 14 Oct. 2019)
Sozinova, O. (2016). Complex Networks-Based Approach to Russian Rhyme History Description: Linguostatistics and Database. In Digital Humanities 2016: Conference Abstracts. Jagiellonian University & Pedagogical University, Kraków, pp. 891-893.
Sonderegger, M. (2011). Applications of graph theory to an English rhyming corpus,
Computer Speech & Language, Volume 25, Issue 3, 2011, pages 655-678, ISSN 0885-2308, https://doi.org/10.1016/j.csl.2010.05.005.