1. Abstract
Introduction
A persisting problem in near eastern studies is the existence of broken cuneiform tablets (listing 1.1). In recent years efforts have been undertaken to 3DScan Mara et al. (2010), to paleographically describe Homburg (2019) and to digitally recon- struct broken fragments Collins et al. (2014, 2017) of cuneiform tablets. However, not always broken fragments can complement each other and often parts of the cuneiform tablet remain destroyed. These fractures or gaps in the cuneiform tablet are not always easy for scholars to fill and take a considerable amount of interpretation time on their part. With the emergence of more digitally available cuneiform text resources, this publication sees an opportunity to investigate if auto-complete algorithms, based on machine learning and linguistic linked open data (LLOD) resources Homburg (2017) can be useful in the reconstruction of cuneiform texts. The classification results are to be used to create a epoch and language specific recommendation system to fill gaps on cuneiform tablets, therefore assisting cuneiform scholars.
Related Work
Related work has been done in autocompletion systems which face the similar challenge of anticipating the users input derived from context and other features Leung & Zhang (2008), Gikandi (2006), Hyvönen & Mäkelä (2006). Those tech- nologies are heavily relied on in input method engines1 which are powered with different dictionary-based algorithms, but recently Chen et al. (2015), Huang et al. (2018) also with machine learning approaches and neural networks. Input method engines for cuneiform have been developed by Homburg et al. (2015).
Methodology
Following Homburg & Chiarcos (2016) machine learning methods applied are either based on grammatical rules (POSTagging), dictionary-based methods ex- ploiting (third-party) dictionary resources or statistical approaches using the following types of machine learning features: – Context-dependent features: e.g. for Hidden Markov Model Classifications – Grammatical features derived from POSTaggers – Semantic Features derived from the semantic meaning of surrounding words – Metadata Features e.g. text categorizations – Paleographic Features using PaleoCodage for a subset of manually annotated texts Homburg (2019)
Experimental Setup
The effectiveness of the algorithms and features is tested on a corpus of all CDLI texts in ATF which is split in a training and test set. Texts are prepared with random gaps for classification and evaluated using the original texts (the gold standard) on unicode cuneiform and on the respective cuneiform transliteration for different cuneiform languages (Sumerian, Hittite, Akkadian) and epochs. The poster features selected peliminary results of the classification and a significance analysis of the features for further discussion for improvement. A possible future goal could be a shared task to improve classification accuracy similar to the cuneiform language identification challenge Jauhiainen et al. (2019)Application
Lastly, the poster presents a prototypical application (fig. 1) displaying the results of the machine learning process which is currently in devel- opment. The implementation builds up on the concept of input method engines Homburg et al. (2015) and will provide a self-learning component.
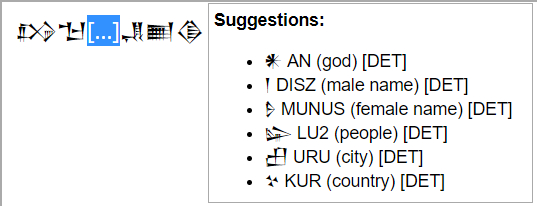 Figure 1: Text Completion Prototype: ”If...Enlil”. The dictionary knows, that Enlil
is a gods name (NE) and is commonly preceded by a determinative character for god
𒀭(an), which is suggested in first place to fill the gap. Next likely options are a
person named Enlil (male or female), the people (tribe) of Enlil, or a location
Figure 1: Text Completion Prototype: ”If...Enlil”. The dictionary knows, that Enlil
is a gods name (NE) and is commonly preceded by a determinative character for god
𒀭(an), which is suggested in first place to fill the gap. Next likely options are a
person named Enlil (male or female), the people (tribe) of Enlil, or a location
Bibliography
Chen, S., Zhao, H. & Wang, R. (2015), Neural network language model forchinese pinyin input method engine, in ‘Proceedings of the 29th Pacific Asia
Conference on Language, Information and Computation’, pp. 455–461. 2
Collins, T., Woolley, S. I., Ch’ng, E., Hernandez-Munoz, L., Gehlken, E., Nash,
D., Lewis, A. & Hanes, L. (2017), A virtual 3d cuneiform tablet reconstruc-
tion interaction, in ‘Proceedings of the 31st British Computer Society Human
Computer Interaction Conference’, BCS Learning & Development Ltd., p. 73.
1
Collins, T., Woolley, S. I., Munoz, L. H., Lewis, A., Ch’ng, E. & Gehlken,
E. (2014), Computer-assisted reconstruction of virtual fragmented cuneiform
tablets, in ‘2014 International Conference on Virtual Systems & Multimedia
(VSMM)’, IEEE, pp. 70–77. 1
Gikandi, D. (2006), ‘Predictive text computer simplified keyboard with word and
phrase auto-completion (plus text-to-speech and a foreign language translation
option)’. US Patent App. 11/308,013. 2
Homburg, T. (2017), Postagging and semantic dictionary creation for hittite
cuneiform, in ‘DH2017’. 1
Homburg, T. (2019), Paleo codage - a machine-readable way to describe
cuneiform characters paleographically, Utrecht, Netherlands.
URL: https://dev.clariah.nl/files/dh2019/boa/0259.html 1, 3
Homburg, T. & Chiarcos, C. (2016), Word segmentation for akkadian cuneiform,
in ‘LREC 2016’. 3
Homburg, T., Chiarcos, C., Richter, T. & Wicke, D. (2015), ‘Learning cuneiform
the modern way’.
URL: http://gams.uni-graz.at/o:dhd2015.p.55 2, 4
Huang, Y., Li, Z., Zhang, Z. & Zhao, H. (2018), ‘Moon ime: neural-based chinese
pinyin aided input method with customizable association’, Proceedings of ACL
2018, System Demonstrations pp. 140–145. 2
Hyvönen, E. & Mäkelä, E. (2006), Semantic autocompletion, in ‘Asian Semantic
Web Conference’, Springer, pp. 739–751. 2
Jauhiainen, T., Jauhiainen, H., Alstola, T. & Lindén, K. (2019), ‘Language and
dialect identification of cuneiform texts’, arXiv preprint arXiv:1903.01891 .
3.1
Leung, B. & Zhang, Q. (2008), ‘Providing relevant text auto-completions’. US
Patent App. 11/751,121. 2
Mara, H., Krömker, S., Jakob, S. & Breuckmann, B. (2010), Gigamesh and
gilgamesh:–3d multiscale integral invariant cuneiform character extraction, in
‘Proceedings of the 11th International conference on Virtual Reality, Archae-
ology and Cultural Heritage’, Eurographics Association, pp. 131–138. 1