1. Abstract
Structuring large historical corpora that are too big to be processed manually can take two approaches. The first is an inductive method extracting implicit entities and meaning from textual (and sometimes visual) content. With the help of AI or manually compiled (existing) lists of entities, the entities are converted into information. The second, that Colavizza (2019) calls referential information systems, takes existing reference systems (like archival indexes) and uses them to contextualize individual documents. Both methods are used to turn corpora into computer accessible information systems. Ideally a more complete information system would result from combining both approaches, but in practice they are hard to bridge because of a number of different problems. This paper presents an approach that addresses those problems and combines inductive methods of automated text analysis and information extraction techniques with knowledge of the referential information systems to add rich semantic layers of information to large historical corpora.
Making large historical corpora accessible for research usually involves a pipeline of processing steps, ranging from text recognition to entity and event spotting, disambiguation, identification and ideally contextualization (Meroño-Peñuela et al. 2015). In many projects much effort is spent on producing a close-to-perfect text by transcribing, or by a mixed procedure of automatic transcription by Optical Character Recognition (OCR) or Handwritten Text Recognition (HTR) and manual correction of the results, as many of the later elements in the pipeline require high-quality text to work well. There are ways to partially solve OCR or HTR (Handwritten Text Recognition) errors automatically through post-correction (see e.g. Reynaert 2014, Reynaert 2016), or to use word embeddings to overcome matching problems, (e.g. Egense 2017). The most important limitation of this approach is that full-text alone is not enough to make a corpus available for research that is not primarily directed at the text but rather at its information (Hoekstra and Koolen 2018, Upward 2018). Extracting and contextualizing information has many issues such as OCR and HTR errors that make it difficult to use standard Natural Language Processing (NLP) tools like Named Entity Recognition (NER), topic modelling, Part Of Speech (POS) tagging and sentiment analysis, which has been common knowledge for a long time (Lopresti 2008, Traub et al. 2015, Mutuvi et al. 2018, Hill & Hengchen 2019, van Strien et al. 2020). However, solutions for such issues are scarce and badly documented, as argued by, amongst others, Piersma and Ribbens (2013), van Eijnatten et al. (2013) and Leemans et al. (2017).
Many archives and libraries have experimented with giving access to their collections by means of their digitized inventories and some have gone a step further, using existing indexes of serial collections (Jeurgens 2016, Colavizza 2019, Head 2003). But these archival referential systems are too coarse for access beyond the document level. However, the existing scholarly apparatus consists of many more reference systems and tools that can be put to good use. Centuries of dealing with these complications have led to a number of convenient and often-employed structures that are part of the printed culture but are often ignored in the translation to digital access (Upward 2018, Opitz 2018).
Exploiting Referential Information Systems and Repetitive Phrases
Instead of trying to find latent semantic structures through full-text analysis, these explicit structures allow for finding intended semantic information that is likely not available in another form. Remarkably, many digitization programmes take no advantage of these structures and sometimes do not even digitize them, extracting only the main textual body as plain text.
A concrete and relatively simple example, the Resolutions of the Dutch States General is a collection of all resolutions (decisions) of the Dutch Republic from 1576 until 1796 and contains around 440,000 pages. Roughly half of the pages, up to 1703, are handwritten. From 1703 onwards, the States General printed yearly editions for easier access to previous resolutions. The States General met six days a week and kept a list of who was present on what date, followed by a summary of each resolution. The left side of Figure 1 shows one column from the printed edition of 1725 with the meeting date, attendants list and some of the resolutions. On the right side is a column from an index page with indexed terms and page references.
Typical steps in digitizing such a large resource are the identification of columns on the page and OCR of the text to make it full-text searchable. Most typically NER would be applied to automatically identify named entities, even if its success depends highly on the OCR and HTR quality. With an estimated 1.5 to 2 million mentions of person names and close to half a million geographic names and organisations, NER would result in a huge list of names, with many false positives (incorrect names) and false negatives (unrecognised names). One issue is that NER tools tend to use uppercase initial letters as a signal that a word is a name, but in early modern texts, uppercase was used for many nouns as well. The most frequently recognized person names then tend to be terms that were often mentioned, like Money, Passport and Meeting. The main problem is that there is no way to predict which names are correct and which are not so users cannot easily filter out the obvious errors from the hundreds of thousands of distinct names. Using reference tools with lists of known historical persons for identification has the limitation that they cover only a small selection of the most famous names, which are not necessarily the most relevant names.
We argue that projects should focus more energy on extracting and operationalizing the existing structure of such corpora. In the case of the resolutions, there is a lot of value in recognizing the meeting dates, attendants lists and index terms.

Figure 1. A column from a resolution page (left side) with meeting date, attendants list and resolutions, and a column from an index page (right side) with indexed terms and page references.
As the resolutions have a fixed format, this allows for segmenting the printed pages using a lot of fixed formulas indicating 1) the start of a new session, 2) a list of representatives attending the session, 3) a number of propositions, that end with an indication of the state of decision (accepted, rejected, or on hold). Finding these parts of text entailed using the paragraphs of the OCRed text and their visual characteristics to identify them. These visual clues were meant to guide contemporary users through the text and find important information quickly. Two examples illustrate this:
For the attendance list the capitalized words “PRAESIDE” for the president and “PRAESENTIBUS” for the common members. While these words often did not come out correctly in the OCR process, their place and capitalization made it easier to find them using approximate heuristic tools and in this way identify the attendance lists.
Similarly, to determine the chronologically ordered sessions across the pages, we used an iterative approach in which first a rough list of dates for sessions was identified (Table 1), which in a second pass could be completed for the missing sessions, that we then knew to be within a specific range of pages.
We treat the extraction of information as a text collation problem (Gilbert 1973): the resolutions have textual overlap when it comes to the start of a meeting day, the introduction of each individual resolution and its decision paragraph, with some unknown amount of textual variation (including variation in spelling, phrasing and text recognition errors), and the aim is to identify and align the textual repetitions and variations.
The formulaic expressions in the resolutions makes them good candidates for fuzzy searching. In this paper we discuss the methods we developed and the evaluation results of applying them on 100,000 pages and roughly 50 million words of resolution text of the printed resolutions from 1703 until 1796. This same principle was used on the entities in the resolutions. The important persons, institutions and subjects figuring in the resolutions were summarized in the index in the front of the book, with references to the pages. They give both the terms and the location where to find them in the text, which makes it much easier to find them using approximate matching.
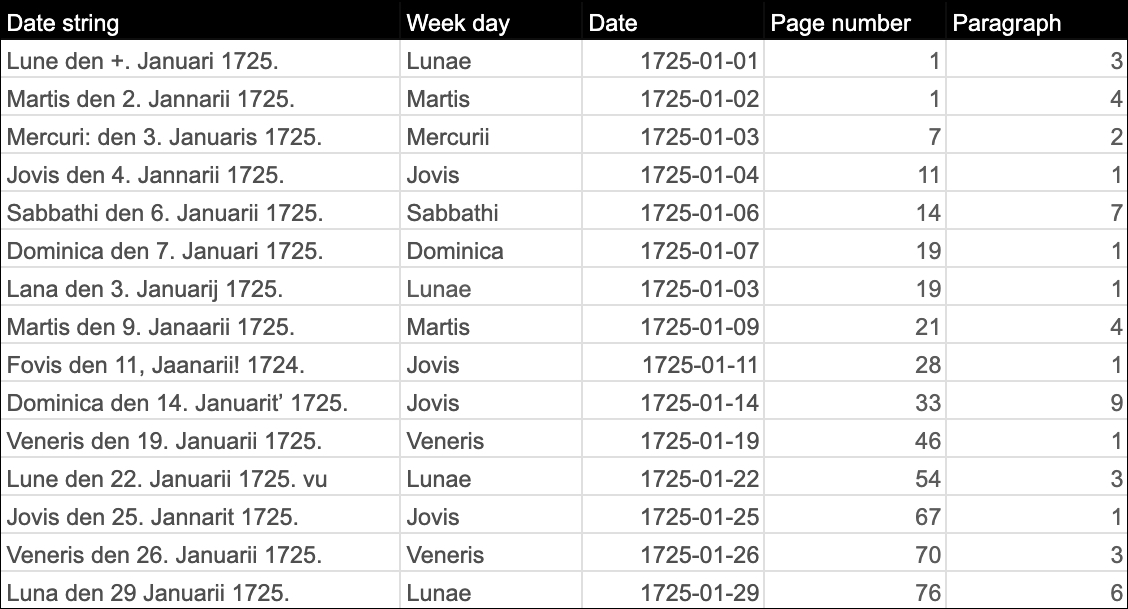
Figure 2. Extraction of meeting date metadata and the page and paragraph number where the resolutions of that day start. Column 1 contains the meeting date as found in the OCR output.
Adding Domain-Specific Semantics to Extracted Information
The fuzzy searching algorithm takes as input a manually created phrase model, which is a list of keywords and phrases of interest, where each entry can have an optional list of alternative phrases or spellings, and uses character skip-grams to find candidate strings in the text for each phrase in the model. The searcher can be configured with different thresholds for edit distance and length variations (candidates may be shorter or longer than the phrase in the model).
We used fuzzy string searching to identify formulaic expressions and iteratively built a corpus-specific phrase model with which we identify:
the date and attendance list of each meeting, which are followed by all the resolutions of that day,
resolution boundaries, e.g. where they start and stop in the running text, so we know which text belongs to which resolution,
different types of opening phrases that correspond to different types of sources (e.g. requests, missives, reports, etc., see Figure 2), and
the decision paragraphs that state what decision, if any, was reached.
By recognizing the opening of a meeting, we know that the mentioned date is the meeting date, which allows us to not only recognize the date, but also adding a label for what the date refers to.
The attendants lists follow the opening of the meeting, and are structured. The first person mentioned is the president, so the recognized name can be labelled with the role of president. The function of president rotated by week among the provinces and presidents therefore also appear as common delegates in other weeks, where they can be found. This leaves a number of unidentified names to spot. All attendants are grouped by province, so can be labelled with their role as attendant of the meeting and with the province they represent. We have lists of all delegates in the meetings of the States General including years and province, that can be used to identify delegates. As a bonus, many delegates also appear in the resolutions in other roles as commissioners or representatives of the States.

Figure 3. Subsequent stages of spotting delegates in the attendance lists
We can add these elements as meaningful metadata labels to individual resolutions, which aids subsequent information access and analysis. Moreover, we can use the consistency of the structure of the resolutions to spot errors. For instance, we can check for cases where an opening formula was found but no decision formula. Or check for missing meeting dates by temporally ordering the ones we did find, or check for OCR errors in delegate names that occur often. In other words, the ‘messy’ output of the OCR process is turned into what Christoph Schöch (2013) calls ‘smart data’, i.e. cleaned, structured and semantically explicit layers of metadata.
Results and Evaluation
We built ground truth datasets to evaluate the different elements of our extraction pipeline: 1) traditional NER using only the resolution text to demonstrate the problems encountered with conventional NLP tools, 2) the identification of page types (index page, resolution page, title page), and 3) the phrase model and the fuzzy searching and extraction process for identifying the meeting dates and the individual resolutions and decisions.
For NER, we labelled all named entities in 200 manually transcribed resolution pages. We re-trained the Spacy NER tagger for Dutch using 10-fold cross validation, taking 90% of the pages for training in each fold, and the remaining 10% for testing. Even though these pages have no OCR errors (but no doubt some transcription errors), the best training run resulted in an F1 score no higher than 0.28 (with a precision of 0.49 and recall of 0.19). Although this can probably be improved with more training data, we conclude that this traditional NLP approach is not suitable for providing high-quality information access.
For the page type identification, we randomly sampled 1696 scans with 3376 pages (most scans contain two pages, some only a single front or back cover) and manually annotated the page type of each page. In the first step, we used layout analysis and fuzzy matching of our phrase models, which achieved an accuracy of 0.91. In the second step, we used the title pages to identify different parts of each book (e.g. the section of index pages, the section of resolution pages) and in each section chose the most frequent page type as the correct page type for all pages in that section. This increased the accuracy to 0.99.
For the ground truth for meeting dates and resolutions, we randomly sampled 300 historical dates in the period 1703-1796, locating the pages containing the resolutions for those dates, and manually annotated the opening of the meeting, the attendance list and all resolution openings and decisions. For the meeting dates and attendance lists, our domain model and fuzzy searching approach reached a precision of 99% and recall of 93%. For the resolution openings and decisions, we reached a precision of 90% and recall of 68%. We have not yet modelled insertions of extracts and letters, and therefore have not evaluated those aspects yet. We are in the process of building a ground truth dataset for the attendants lists.
Reusability and Generalisability
Extracting semantic information requires heuristics for specific digitized resources. Generic approaches of layout analysis can detect standard structures like tables, figures, footnotes, headers and tables of content (Doermann and Tombre 2014, Clausner 2019), but cannot interpret specific semantics such as temporal orderings of meeting dates and the geographical ordering in the attendants lists.
The page identification rules and phrase model we developed in the Republic project are specific for the Resolutions of the States General, but the general method is reusable. Many large-scale resources have an internal structure that was created to enhance accessibility. Often, they were part of an information system designed for an analog, or ‘paper’ age, but it pays off to devise ways to transfer this to a digital equivalent. Devices like indexes contain a wealth of information about a resource, its context and its use. In many official resources corpus-specific phrases are used that may be categorized and used for searching. As there is often a degree of variation, the extraction process requires fuzzy searching and matching. Our fuzzy searching module is configurable, with matching thresholds that can be adapted to the peculiarities of the corpus or even to specific parts of the corpus. Fuzzy searching can also help to overcome the limitations of inaccurate OCR and HTR.
Beyond the Republic project, we have used this approach for a number of projects. For example, we have used it for books with medieval charters, in which the standard charter structure allows us to date the 17,000 historical place names mentioned in those charters and use them as place name attestations in historical gazetteers. Another example is the standard structure of advertisements of auctions in 18th century Dutch newspapers, in which brokers, auction date and venue and the auctioned goods can be extracted with a simple phrase model despite high character error rates.
A limitation of our method is that it does not work out-of-the-box but requires a corpus-specific phrase model, as existing information systems and structures are specific to the resource and require information extraction techniques to be adapted to corpus. This requires an iterative approach in which the models will be evaluated and refined. Standard phrases occur in many corpora, but they are usually corpus-specific. Furthermore, even this approach requires a minimum quality of text recognition to have enough contextual information for recognizing phrases.
Our method is still in development, but we think it is possible to make a toolkit with components that are relevant and reusable for many corpora. For different corpora, using the toolkit will be a matter of tuning the components. However, this must be done programmatically; we think that using an approach using just graphical user interfaces would obscure too many of the features and the implications of tuning. For evaluation of intermediate results in the iterative process, however, existing tools can be used.