1. Abstract
“Telling bigger stories”: Formal ontological modelling of scholarly argumentation
Introduction and problem statement
This paper presents completed work on formalizing scholarly argumentation in literary studies in the form of knowledge models. It argues that by adopting formal ontological modelling1, not only can we make scholarly argumentation conducive to long-term preservation and ongoing participation in the scholarly discourse, but also make it the starting point for genuinely collaborative research endeavours. Moreover, by virtue of their ontological foundation, knowledge models ideally represent reproducible interpretative processes.
Knowledge modelling has been an ongoing field of research in the digital humanities for many years. Flagship projects such as ResearchSpace2 have helped to popularize the concepts of semantic integration and to make the benefits of this approach tangible for the research community. While there has been acknowledgement of the importance of formalization of scholarly argumentation in both literary studies and digital humanities3, there have been a number of practical and ideological barriers to its realization. The former often relate to the perceived steep learning curve associated with ontologically underpinned knowledge modelling, the latter to a perceived infringement of scholarly expressivity and freedom. This paper addresses both concerns by integrating an easy-to-use modelling tool with a literary corpus, highlighting opportunities for beneficial formalisms, clarity, and precision of expression wherever possible, so users are enabled to collaboratively create and collectively benefit from improved knowledge representations.
In the context of the research strand of the Eighteenth-Century Poetry Archive (ECPA) project4, I have developed a Web-based knowledge modelling tool intended to enable literary scholars to model their argumentation about the poems in the database.5 I will demonstrate that as a form of integrated knowledge representation, visualization, and preservation, the knowledge models created can both express and integrate different (including contradictory) argumentative strands.
The tool thus encourages intersection of otherwise dispersed and isolated scholarly arguments, the breaking up of intellectual silos, and helps towards dispelling the persistent myth of the lone scholar in the humanities. In the spirit of the conference theme, the paper touches on many aspects of the open data movement that underpin and are prerequisites for this work, such as Open Access, Open Scholarship, and Open Standards (such as LOD, shared ontologies, taxonomies, and vocabularies).
Approach and implementation
The ECPA knowledge modelling tool facilitates and encourages the creation of models that
focus on different aspects of a poem, yet are all collectively modelling the object of study and all arriving at ever more sophisticated and comprehensive models. It is through formalization using shared conceptualizations, that the models created remain useful beyond the original context and purpose of their creation. They can thus be shared, re-used, adapted (forked), enhanced, aggregated, and even developed collaboratively.
The ECPA modelling tool is both a modelling and publishing platform. As such, it offers a number of workflow management options that support the entire modelling process, from inception through to publication. It has been designed in a way that is easy to grasp, learn, and perform. Its layout consists of a number of workflow buttons (e.g. fork, close, save, download, publish) along with the model itself in both its graph representation6 and a control panel, which provides information about the model, a representation of the model's components (classes, instances, and statements) in text form, and an editing tool.
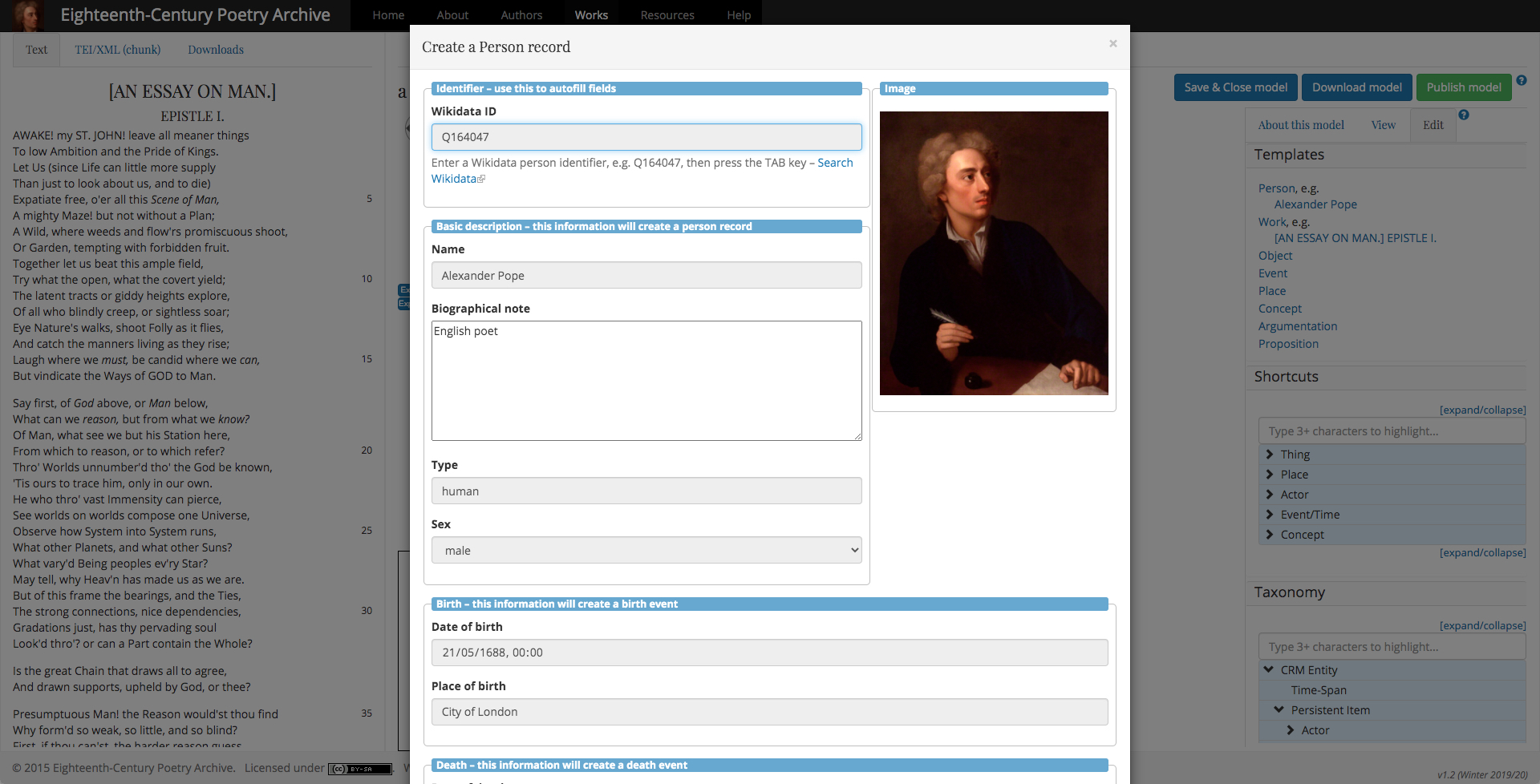 Figure 1: Template for a person record pre-filled with Wikidata information
Figure 1: Template for a person record pre-filled with Wikidata information
The editing tool offers three related approaches to the creation of the instances (individuals) and relations that together form a scholarly argument. Firstly, a number of templates are provided for some of the key ontological classes frequently used in modelling (currently, persons, works, objects, events, places, concepts, and argumentation). These templates can be auto-filled from Wikidata representations of the items where available. Secondly, the tool offers a number of shortcuts7, which provide a convenient way of connecting common classes in standardized ways. Shortcuts are currently provided between things, places, actors, events/time, and concepts. Each shortcut takes the form of a path of one or more statements (triples) that follow on from each other. Thirdly, the full expressivity of the ontology is available by using a taxonomy tree display of the classes in the project's ontologies, which provides the most granular modelling option. The best results are often achieved by using the three approaches (templates, shortcuts, and taxonomy) in parallel.
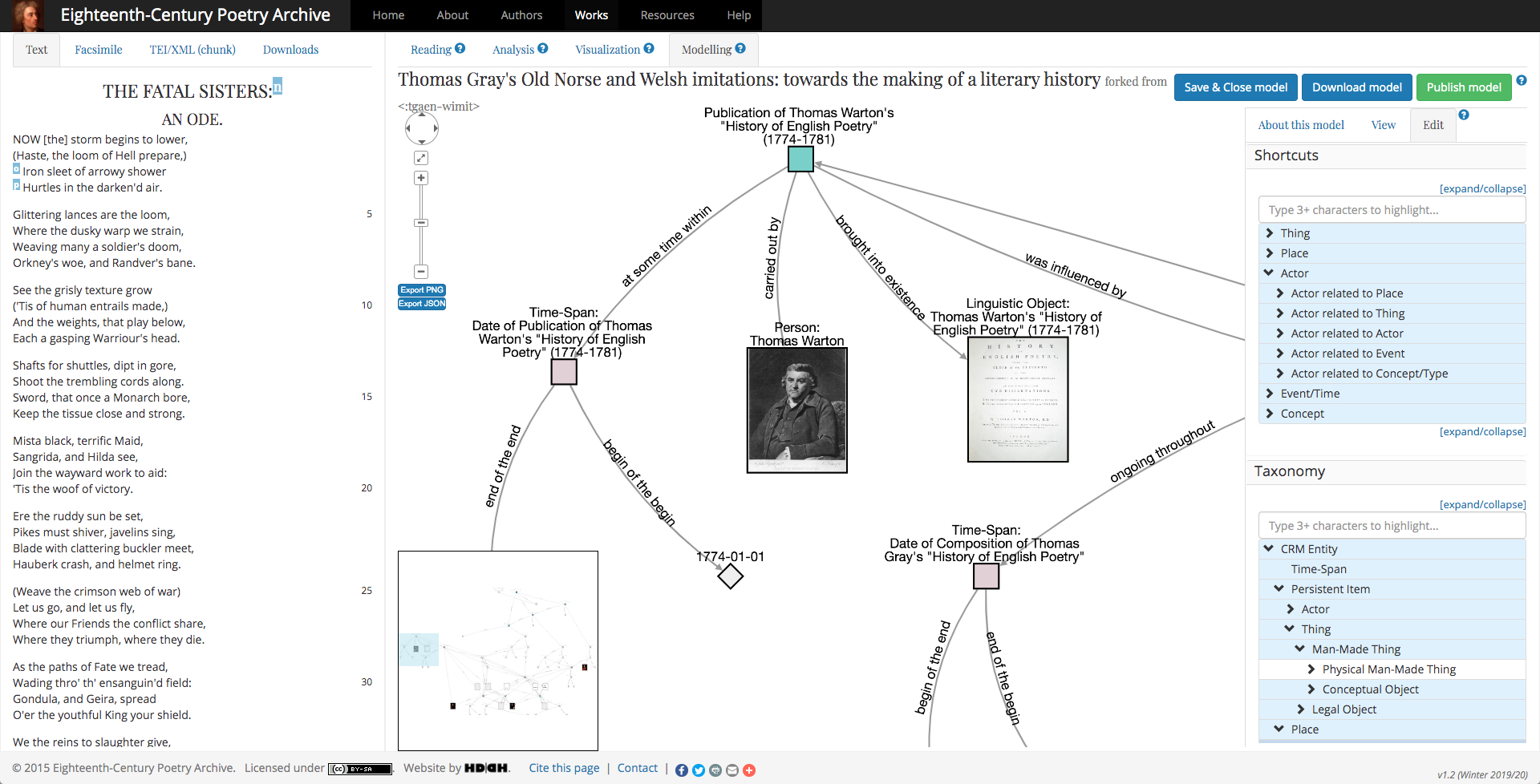 Figure 2: Part of a knowledge graph with ontology shortcuts and taxonomy tree in the editing view
Figure 2: Part of a knowledge graph with ontology shortcuts and taxonomy tree in the editing view
The modelling process is augmented by a context-sensitive interface throughout, which offers definitions of classes, scope information, and help texts. As instances are added to the knowledge base, these are used to populate data lists that can be used to speed up the process of filling in the forms to create the triples.
Contribution and further work
The ECPA modelling tool presented here takes knowledge modelling as a method of semantic integration and applies it in an integrated manner to the literary study of a coherent corpus of eighteenth-century poetry, thus arriving at a fully-fledged implementation of a research environment for literary scholars8, which enables the creation, representation, and long-term preservation of the scholarly analysis of the poems. Most importantly, as a participatory methodology to produce and organize shared knowledge, it facilitates new types of collaboration.
By making our research reproducible, extensible, and thanks to the ontological underpinnings, machine-understandable, we also embrace the machine's capacity for reasoning as an important way of producing new insights. Once a big enough set of models has been created, we can use computers to analyse them, reason upon them, and help us to not only store these knowledge bases, but build on them to create new knowledge. This step connects to ongoing efforts, primarily in scientific, legal, and medical contexts, to arrive at formalized argumentative models through context-guided argumentation mining. Underpinning these efforts with a common ontology should contribute to a set of coherently structured if unevenly granular knowledge representations. Ultimately, I expect these models to constitute a dataset that will be useful for the computationally-assisted interpretation of the poems. I hope to show that knowledge models are thus ideally suited not only to enhance our ability to ask bigger questions by semantically integrating different strands of scholarly arguments, but also through sharing and collaboration, aggregation and combination are capable of telling bigger stories.
The paper will demo the research environment, will cover the technology layer underpinning it (RDF store and library, triple generation, graph representation, and interface components such as serializations and storage formats), and will report on outreach efforts and uptake.
Notes
- I have adopted the CIDOC-CRM family of ontologies as core ontologies for this work: http://www.cidoc-crm.org/collaborations
- https://www.researchspace.org/
- As early as 1990 Helmut Bonheim has argued for the benefits of formalization in literary studies in his book Literary Systematics (Cambridge, 1990). The field of Digital Humanities has long acknowledged the centrality of knowledge modelling as one of its core activities, pertinent contributions by Willard McCarty, Øyvind Eide, and Fabio Ciotti, among others testify to its centrality.
- Eighteenth Century Poetry Archive https://www.eighteenthcenturypoetry.org/
- There is no reason why this tool couldn’t be published in a generic stand-alone fashion, however, its integration with a literary corpus as well as other tools such as close reading and visualization tools in ECPA provides benefits of contextualization not otherwise easily achievable.
- Via Cytoscape.js http://js.cytoscape.org/
- These shortcuts are based on the CIDOC-CRM's idea of using "Fundamental Categories" (FC) and "Fundamental Relationships" (FR) for querying CRM-based repositories.
- The ECPA project has been integrating digital tools into its textual corpus from inception, firmly believing that it is through integration of object and tool we achieve deeper contextualization and better outputs.
Bibliography
- Bartalesi, Valentina and Carlo Meghini. “Using an Ontology for Representing the Knowledge on Literary Texts: the Dante Alighieri Case Study”. Semantic Web 1 (2015): 1-10. Web. 29 Aug. 2018. http://www.semantic-web-journal.net/content/using-ontology-representing-knowledge-literary-texts-dante-alighieri-case-study-0
- Beynon, Meurig, Steve Russ and Willard McCarty. “Human Computing—Modelling with Meaning”. Digital Scholarship in the Humanities 21(2) (2006): 141-157. Web. 18 Aug. 2017. https://doi.org/10.1093/llc/fql015
- Bonheim, Helmut. Literary Systematics. Cambridge: D. S. Brewer, 1990. Print.
- Ciotti, Fabio. “Digital methods for Literary Criticism”. Lecture slides. University of Rome Tor Vergata, 2015? Web. 29 Aug. 2018. http://didattica.uniroma2.it/files/scarica/insegnamento/161783-Informatica-Umanistica-Lm-Per-Il-Llea/37175-Slide
- Ciula, Arianna and Cristina Marras. “Circling around texts and language: towards 'pragmatic modelling' in Digital Humanities”. Digital Humanities Quarterly (DHQ) 10.3 (2016). Web. 18 Aug. 2017. http://www.digitalhumanities.org/dhq/vol/10/3/000258/000258.html
- Ciula, Arianna and Øyvind Eide. “Modelling in digital humanities: Signs in context”. Digital Scholarship in the Humanities 32 (2017): i33–i46. Web. 18 Aug. 2017. https://doi.org/10.1093/llc/fqw045
- Ciula, Arianna, Øyvind Eide, Cristina Marras, and Patrick Sahle, eds. Models and Modelling between Digital and Humanities — A Multidisciplinary Perspective. Historical Social Research (HSR) Supplement 31 (2018). Print.
- Eide, Øyvind. Media Boundaries and Conceptual Modelling: Between Texts and Maps. Pre-print manuscript, Apr. 2015. Web. 7 Jan. 2019. https://www.oeide.no/research/eideBetween.pdf
- Kräutli, Florian and Matteo Valleriani. “CorpusTracer: A CIDOC database for tracing knowledge networks”. Digital Scholarship in the Humanities 33(2) (2018): 336-346. Web. 26 Oct. 2018. https://pure.mpg.de/rest/items/item_2472866_10/component/file_3002633/content
- Lippi, Marco, and Paolo Torroni. “Argumentation Mining: State of the Art and Emerging Trends.” ACM Transactions on Internet Technology 16, no. 2 (March 30, 2016): 1–25. https://doi.org/10.1145/2850417
- McCarty, Willard. Humanities Computing. Houndmills: Palgrave Macmillan, 2005. 20-72. Print.
- Oldman, Dominic, Martin Doerr, and Stefan Gradmann. “Zen and the Art of Linked Data: New Strategies for a Semantic Web of Humanist Knowledge”. Schreibman, Susan, Ray Siemens, and John Unsworth, eds. A New Companion to Digital Humanities. Malden, MA: Wiley Blackwell, 2016. 251-273. Print.
- Pasin, Michele and John Bradley. “Factoid-based prosopography and computer ontologies: towards an integrated approach”. Digital Scholarship in the Humanities 30(1) (2015): 86-97. Web. 29 Aug. 2018. https://doi.org/10.1093/llc/fqt037