1. Abstract
Evaluating a Machine Learning Approach to Identifying Expressive Content at Page Level in HathiTrust
Nikolaus Parulian1, Kristina Hall2, Ryan Dubnicek1, Yuerong Hu1, Stephen Downie1
1 HathiTrust Research Center, School of Information Sciences, University of Illinois at Urbana-Champaign
2 HathiTrust, University of Michigan
Introduction
HathiTrust [1] fully provides scanned images, plain text and metadata in support of their mission to contribute to research, scholarship and the sharing of human knowledge. Since facts, unlike expressive content, are exempt from copyright [2], this project seeks to use machine learning approaches to evaluate how often expressive content appears in the first 20 pages of a given HathiTrust volume, with an eye to potentially making this data open.[3]
Information contained in the first 20 pages of a volume can be useful to scholars. For example, the title page, table of contents, or acknowledgment page may contain useful information to understanding the volume. However, it is likely that some volumes include materials that have copyright protection in this same range. Some observed copyrighted materials in this page range are illustrations or even the main text itself [4]. One method to understand if expressive content is exposed in the first 20 pages would require manual page labeling, which is time-intensive. A machine learning approach is more efficient and could be well-suited to this type of prediction task [5], and we seek to answer these research questions:
- Can we develop a machine learning approach to help detect expressive contents in the first 20 pages of HathiTrust volumes?
- How reliably does this approach match manual labeling data?
Methodology
Providing a high-quality dataset for training the machine learning model is essential, and human expertise is required. We manually sampled 900 volumes from HathiTrust and labeled each of the first 20 pages: either as 'factual' for a page with contents lacking creative expression and 'creative' if there is protected material on the page. Then we developed a workflow to use the statistical features of the page from the HathiTrust Research Center (HTRC) Extracted Features Dataset [6] as additional data to train our model. The features used included: token and line counts, tokens per line, and begin and end line characters.
Using the features above, we trained and compared four basic classification models on our feature set: Random Forest, Logistic Regression, Support Vector Machine, and Stochastic Gradient Descent [7]. Through this comparison we hope to both find the most accurate model as well as generally evaluate if a machine learning approach can be accurate for this task. The preliminary results of our prediction model can be seen in Figure 1.
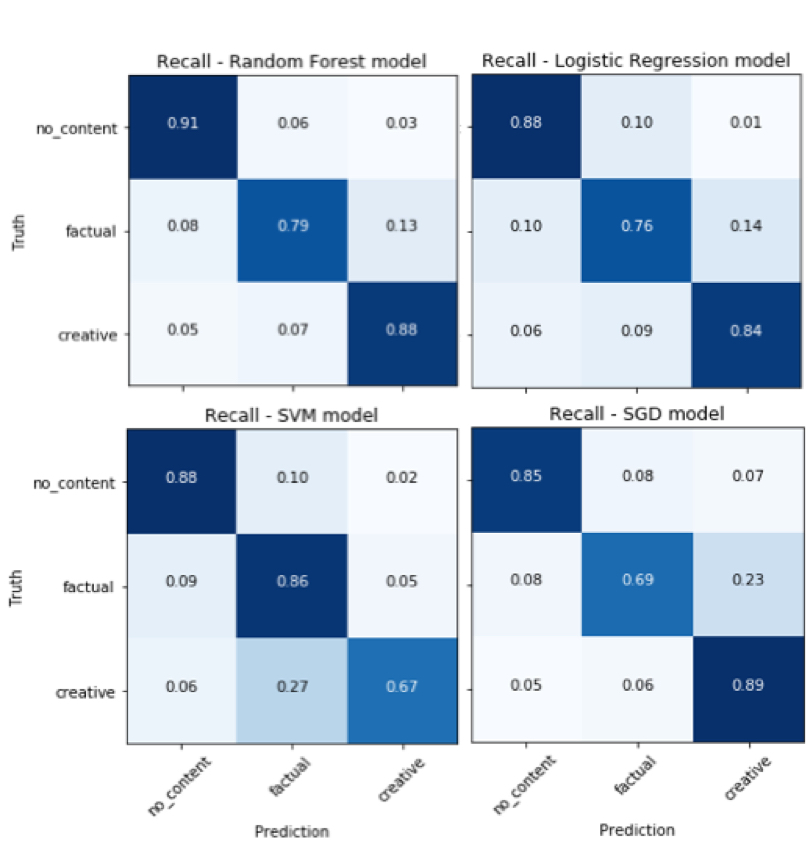
Figure 1: Confusion Matrix for four models for predicting creative (protected) content
Conclusion and Future Work
Results suggest that the Random Forest model performs best in both accuracy for predicting all labels (86%) and recall (0.88) for predicting creative content. For this project, we give more attention to the recall on the 'creative' label because a false negative on this label is a less desirable outcome. Future goals of this work are: to pilot different methods that can increase confidence in determining creative content, such as deep learning and utilizing page text, and to increase the scope of this prediction beyond our test set to a larger set of HathiTrust volumes.
References
- https://www.hathitrust.org/
- Justia Law. “Feist Pubs., Inc. v. Rural Tel. Svc. Co., Inc., 499 U.S. 340 (1991).” Accessed October 14, 2019. https://supreme.justia.com/cases/federal/us/499/340/.
- “Operationalizing ‘Non-Consumptive’ Fair Use to Revolut... | HathiTrust Digital Library.” Accessed October 14, 2019. https://www.hathitrust.org/blogs/perspectives-from-hathitrust/operationalizing-non-consumptive-fair-use-to-revolutionize.
- Example volume containing a mix of expressive and factual contents within front matter: https://catalog.hathitrust.org/Record/005323091.
- Lara McConnaughey, Jennifer Dai and David Bamman (2017), "The Labeled Segmentation of Printed Books" (EMNLP 2017)
- Boris Capitanu, Ted Underwood, Peter Organisciak, Timothy Cole, Maria Janina Sarol, J. Stephen Downie (2016). The HathiTrust Research Center Extracted Feature Dataset (1.0) [Dataset]. HathiTrust Research Center, http://dx.doi.org/10.13012/J8X63JT3.
- Pedregosa, Fabian, et al. "Scikit-learn: Machine learning in Python." Journal of machine learning research 12.Oct (2011): 2825-2830.