1. Abstract
Fabian Offert, Peter Bell
Towards Open Computer Vision Methods: Visual Analytics of Machine Learning Models in the Digital Humanities
Interpretable machine learning, also known as XAI (explainable artificial intelligence), has recently attracted a significant amount of attention in the computer science community and beyond (Lipton 2016, Doshi-Velez and Kim 2017, Gilpin et al. 2018, Olah et. al. 2018). As a relatively new sub-field of machine learning, interpretable machine learning aims to find potential solutions to the inevitable opacity of machine learning models applications by mitigating this opacity through the production of “explanations”.
Such a mitigation has become increasingly relevant as machine learning models start to inform socially and politically relevant decision-making processes (Pasquale 2015, Benjamin 2019, Crawford and Paglen 2019).
From the technical perspective, machine learning models thus become “interpretable” if they, either by design or with the help of external tools, can provide human-understandable explanations for their decisions, predictions, or classifications. In the past five years, various techniques have been developed to produce such explanations, including those targeted specifically at machine learning models operating on images, which are often subsumed under the term visual analytics (Hohman et al. 2018). Explanations in the image domain often function as visualizations, showing and thus explaining how a machine learning model arrives at a certain output.
Beyond these technical results, however, a larger conceptual discussion has emerged in the technical disciplines that “infringes” on the terrain of the digital humanities. It is centered around attempts to find quantitative definitions for concepts that naturally emerge from the problem at hand, such as “interpretation” and “representation”, with the help of methods and concepts from disciplines as diverse as psychology, philosophy, and sociology (Kim et. al. 2019, Mittelstadt et. al. 2019, Selbst and Barocas 2018, Ritter et. al. 2017).
Despite the emergence of this cross-disciplinary discussion, however, the interest in interpretable machine learning in the digital humanities community has so far been marginal. Among the few existing studies are Ted Underwood’s recent book (2019), which discusses interpretability in the appendix. Arnold and Tilton (2019) briefly examine interpretability in the context of an analysis of the “deepness” of deep learning methods. Finally, Alan Liu’s recent work on methods that allow a “close reading of distant reading” are also informed by a discussion of interpretability (Liu 2020). Generally, however, the notion of machine learning models as “impenetrable” black boxes (Arnold and Tilton 2019) persists in the digital humanities community.
Counter to this narrative, in this paper, we argue that interpretable machine learning in general, and techniques from visual analytics in particular, can significantly improve digital humanities research by facilitating a critical machine vision approach to image data. We posit that, generally, interpretable machine learning provides a natural bridge between “close” and “distant” methods. In fact, it provides a critical and technical framework to analyze the “distant” methods themselves. As such, it addresses the question of open data from a meta-methodological point of view: if data is open, the methods which process the data need to be open as well. Importantly, this openness has to go beyond open source. It requires the development of tools that actively mitigate the general opacity of computational methods by making them interpretable, and thus allow them to be both tool and subject of a humanist analysis.
Importantly, the opacity of machine learning models is as much a function of the phenomenological differences between human and machine perception as it is a function of model size (Burrell 2016; Selbst and Barocas 2018; Offert and Bell 2020). This is particularly relevant to digital humanities research on image data, where low-level computer vision methods are often employed to generate high-level hypotheses. For instance, it has been recently shown that deep neural networks often prefer textures over shapes (Geirhos et al. 2019), and generally rely on imperceptible image features (Ilyas et al. 2019). Visual analytics methods can discover such phenomenological biases in regard to specific datasets, and thus lower the risk of misguided higher-level conclusions based on machine predictions while not being subject to a trade-off between model capability and interpretability.
In this paper, we present concrete results for the application of the “feature visualization” visual analytics method (Erhan et. al. 2009, Yosinski et. al. 2015, Olah et. al. 2017 ) to machine learning models trained on both a toy art historical corpus and the “standard” ImageNet/ILSVRC2012 dataset (Russakovsky et al. 2015). We demonstrate the potential and limitations of the technique, building upon previous work on attribution (Bell and Offert 2020).
Concretely, we show that feature visualization, as a generative approach, offers intuitively interpretable visualizations, which points to an untapped general potential of generative methods like generative adversarial networks (Goodfellow et al. 2014). Feature visualization allows for the discovery of unexpectedly salient image features which can not be detected with attribution methods, and which mirror the phenomenological biases of the employed machine vision systems. In our experiments, for instance, which extend previous work (Offert 2018), it facilitated the discovery of a heavy emphasis on drapery – i.e. a textural feature, as suggested in Geirhos et al. (2019) – in the detection of portraits, counter to the intuitive assumption that the most salient shared feature of portrait imagery would be found in faces.
Applied to the ImageNet/ILSVRC2012 dataset the political dimension of these phenomenological biases becomes evident, where marginal image subjects heavily influence classification. To demonstrate this, we visualized and selected the output neurons for several classes of an InceptionV3 model (Szegedy et. al. 2016) pre-trained on ImageNet/ILSVRC2012 hand-selecting visualizations that show some non-intuitive properties of the ImageNet dataset.
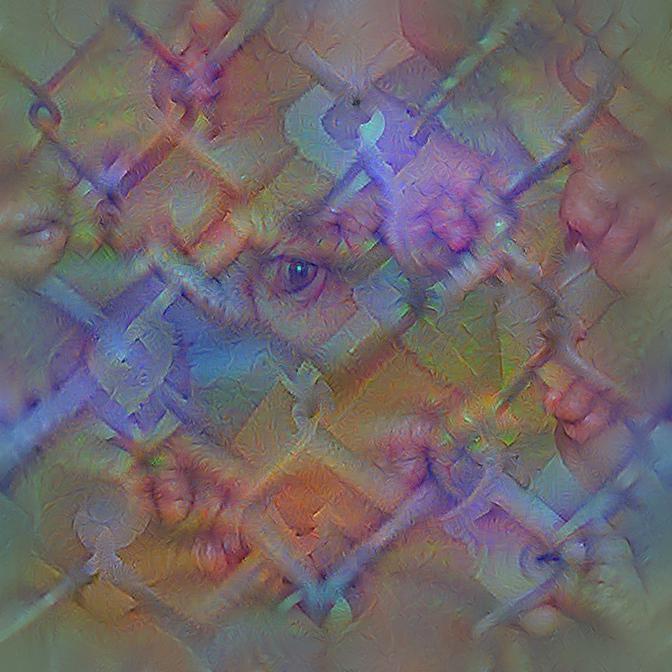 Fig. 1: Feature visualization allows for the discovery of unexpectedly salient image features. Here, a feature visualization of the “fence” class output neuron of an InceptionV3 deep convolutional neural network trained on the ILSVRC2012 dataset shows that, counter to intuition, the detection of fences is influenced by the presence of confined persons, an artifact of the training set. Importantly, this means that the presence of confined persons behind a fence in an image makes that image more fence-like to the classifier.
Fig. 1: Feature visualization allows for the discovery of unexpectedly salient image features. Here, a feature visualization of the “fence” class output neuron of an InceptionV3 deep convolutional neural network trained on the ILSVRC2012 dataset shows that, counter to intuition, the detection of fences is influenced by the presence of confined persons, an artifact of the training set. Importantly, this means that the presence of confined persons behind a fence in an image makes that image more fence-like to the classifier.
For instance, for the “fence” class output neuron (fig. 1) we see that the network has not only picked up the general geometric structure of the fence but also the fact that many photos of fences in the original dataset (that was scraped from the Internet) seem to contain people confined behind these fences. This can be verified by analyzing the 1300 images in the dataset class, which indeed show some, but not many scenes of people confined behind fences. Cultural knowledge, more specifically, a concrete representation of cultural knowledge defined by the lense of stock photo databases and hobby photographers, is introduced here into a supposedly objective image classifier. Importantly, this also means that images of people behind fences will appear more fence-like to the classifier. The relevance of this consequence is revealed by a Google reverse image search: for a sample image (fig. 2) from the “fence class”, despite the prominence of the person compared to the actual fence, the search produces the Wikipedia entry for “chain-link fencing” (fig. 3), suggesting an unverifiable but likely connection between the Google image search algorithm and ImageNet/ILSVRC2012.
 Fig. 2. Sample image from the ILSVRC2012 “chain link fence” class. Note that there are only a few images (between 1% and 5% of the class, depending on what counts as “behind”) that show people behind fences.
Fig. 2. Sample image from the ILSVRC2012 “chain link fence” class. Note that there are only a few images (between 1% and 5% of the class, depending on what counts as “behind”) that show people behind fences.
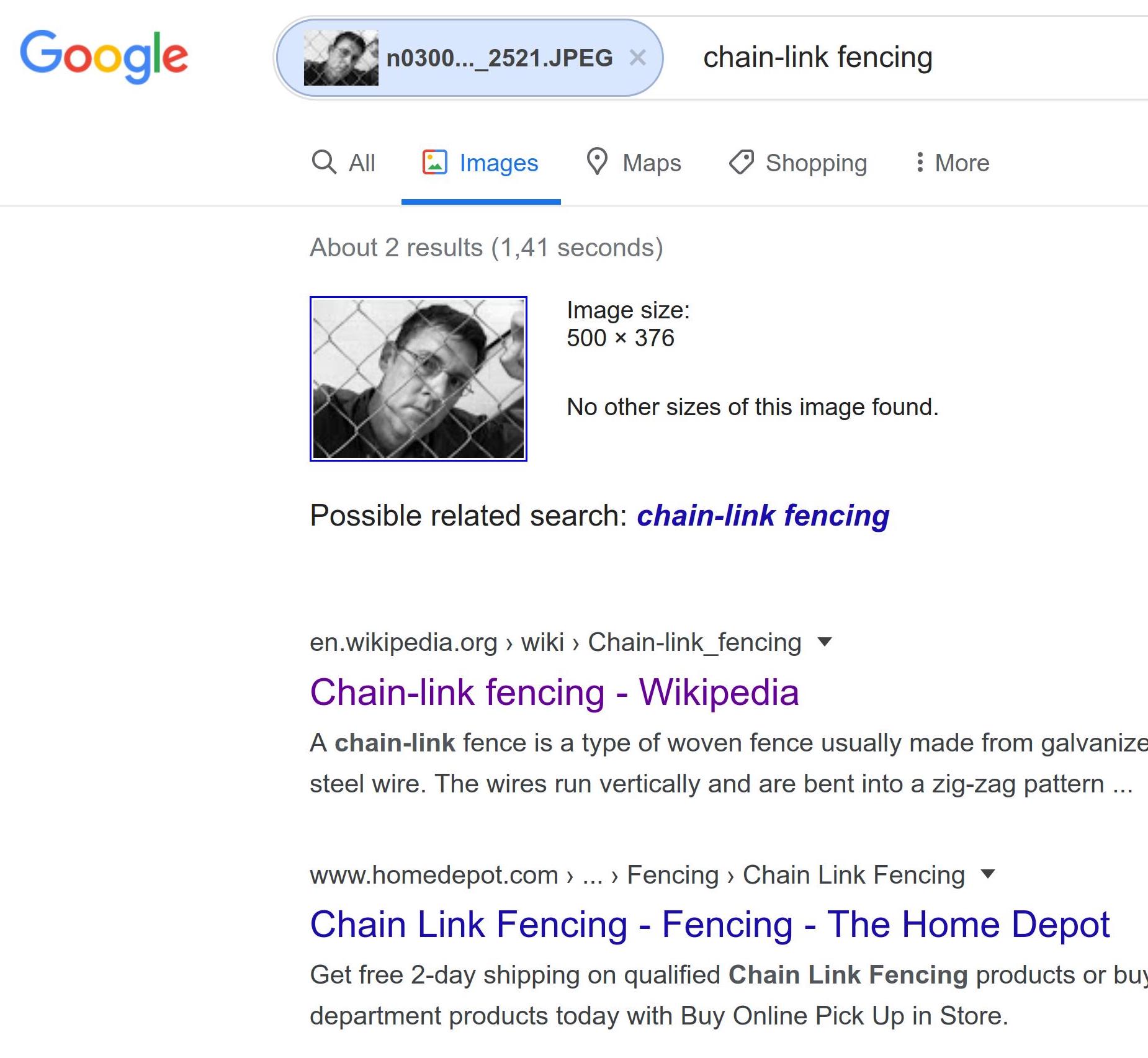 Fig. 3. A Google reverse image search for the selected image, despite the fact that it does not exist on the Internet anymore, and despite the prominence of the person compared to the actual fence, produces the Wikipedia entry for “chain-link fencing”, suggesting an unverifiable but likely connection between the Google image search algorithm and ImageNet/ILSVRC2012. A text search for “chain-link fencing” produces no “people behind fences” scenes.
Fig. 3. A Google reverse image search for the selected image, despite the fact that it does not exist on the Internet anymore, and despite the prominence of the person compared to the actual fence, produces the Wikipedia entry for “chain-link fencing”, suggesting an unverifiable but likely connection between the Google image search algorithm and ImageNet/ILSVRC2012. A text search for “chain-link fencing” produces no “people behind fences” scenes.
Finally, we propose a concrete analytical pipeline for the visual digital humanities that integrates visual analytics by means of open-source tools and frameworks. For instance, tools like summit (Hohman et al. 2019), lucid (https://github.com/tensorflow/lucid), or tf-explain (https://github.com/sicara/tf-explain/) combine feature visualization and attribution methods to enable a fine-grained analysis of how different neurons in a deep neural network contribute to the classification of an image based on its visual features. We discuss the feasibility of this proposed pipeline in regard to different data domains and computer vision approaches.
We conclude that visual analytics could be integrated into many digital humanities projects, and will positively expand the results of future projects, making digital humanities research not only more rigorous but also increasing its scope.
References
Arnold, Taylor, and Lauren Tilton. 2019. “Depth in Deep Learning: Knowledgeable, Layered, and Impenetrable.” https://statsmaths.github.io/pdf/2020-deep-mediations.pdf
Bell, Peter and Fabian Offert. 2020. “Reflections on Connoisseurship and Computer Vision” Journal of Art Historiography, forthcoming.
Benjamin, Ruha. 2019. Race After Technology: Abolitionist Tools for the New Jim Code. John Wiley & Sons.
Burrell, Jenna. 2016. “How the Machine ‘Thinks’: Understanding Opacity in Machine Learning Algorithms.” Big Data & Society 3 (1).
Crawford, Kate and Trevor Paglen. 2019. “Excavating AI: The Politics of Images in Machine Learning Training Sets.” https://www.excavating.ai/
Erhan, Dumitru, Yoshua Bengio, Aaron Courville, and Pascal Vincent. 2009. “Visualizing Higher-Layer Features of a Deep Network.” Université de Montréal.
Doshi-Velez, Finale, and Been Kim. 2017. “Towards a Rigorous Science of Interpretable Machine Learning.” arXiv Preprint arXiv:1702.08608.
Geirhos, Robert, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. 2019. “ImageNet-Trained CNNs Are Biased Towards Texture; Increasing Shape Bias Improves Accuracy and Robustness.” arXiv Preprint arXiv:1811.12231.
Gilpin, Leilani H., David Bau, Ben Z. Yuan, Ayesha Bajwa, Michael Specter, and Lalana Kagal. 2018. “Explaining Explanations: An Overview of Interpretability of Machine Learning.” In 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), 80–89.
Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. “Generative Adversarial Nets.” In Advances in Neural Information Processing Systems, 2672–80.
Hohman, Fred Matthew, Minsuk Kahng, Robert Pienta, and Duen Horng Chau. 2018. “Visual Analytics in Deep Learning: An Interrogative Survey for the Next Frontiers.” IEEE Transactions on Visualization and Computer Graphics.
Hohman, Fred, Haekyu Park, Caleb Robinson, and Duen Horng Chau. 2019. “Summit: Scaling Deep Learning Interpretability by Visualizing Activation and Attribution Summarizations.” arXiv Preprint arXiv:1904.02323.
Ilyas, Andrew, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. 2019. “Adversarial Examples Are Not Bugs, They Are Features.” arXiv Preprint arXiv:1905.02175.
Kim, Been, Emily Reif, Martin Wattenberg, and Samy Bengio. 2019. “Do Neural Networks Show Gestalt Phenomena? An Exploration of the Law of Closure.” arXiv Preprint arXiv:1903.01069.
Lipton, Zachary C. 2016. “The Mythos of Model Interpretability.” In 2016 ICML Workshop on Human Interpretability in Machine Learning (WHI 2016), New York, NY.
Liu, Alan. 2020. “Humans in the Loop: Humanities Hermeneutics and Machine Learning.” DHd2020 Keynote.
Mittelstadt, Brent, Chris Russel, and Sandra Wachter. 2019. “Explaining Explanations in AI.” In ACM Conference on Fairness, Accountability, and Transparency (FAT*).
Offert, Fabian. 2018. “Images of Image Machines. Visual Interpretability in Computer Vision for Art.” In European Conference on Computer Vision, 710–15.
Offert, Fabian and Peter Bell. 2020. “Perceptual Bias and Technical Meta-Images. Critical Machine Vision as a Humanities Challenge”. AI & Society, forthcoming
Olah, Chris, Alexander Mordvintsev, and Ludwig Schubert. 2017. “Feature Visualization.” Distill.
Olah, Chris, Arvind Satyanarayan, Ian Johnson, Shan Carter, Ludwig Schubert, Katherine Ye, and Alexander Mordvintsev. 2018. “The Building Blocks of Interpretability.” Distill.
Pasquale, Frank. 2015. The Black Box Society. The Secret Algorithms That Control Money and Information. Harvard University Press.
Ritter, Samuel, David G. T. Barrett, Adam Santoro, and Matt M Botvinick. 2017. “Cognitive Psychology for Deep Neural Networks: A Shape Bias Case Study.” arXiv Preprint arXiv:1706.08606.
Russakovsky, Olga, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, et al. 2015. “Imagenet Large Scale Visual Recognition Challenge.” International Journal of Computer Vision 115 (3), 211–52.
Selbst, Andrew D., and Solon Barocas. 2018. “The Intuitive Appeal of Explainable Machines.” Fordham Law Review 87.
Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. 2016. “Rethinking the Inception Architecture for Computer Vision.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2818–2826.
Underwood, Ted. 2019. Distant Horizons: Digital Evidence and Literary Change. University of Chicago Press.
Yosinski, Jason, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. 2015. “Understanding Neural Networks through Deep Visualization.” arXiv Preprint arXiv:1506.06579.