1. Abstract
Qualitative interviews constitute an important research tool for disciplines such as history, sociology, ethnology or political science. Yet, despite rare initiatives (Cadorel et al., 2018), transcriptions are scarcely shared with other researchers. And their annotation is most of the time done only for a personal use, without following any sort of standard, and not meant to be shown to anyone.
In this paper, we advocate for the necessity of a more open management of these resources, and present a proposition for a XML-TEI-conformant standard, allowing for their accurate transcription and annotation. The ODD we present is aimed at facilitating systematic analyses of corpora of interview transcriptions, as well as at ensuring a better dissemination and re-usability of these resources. We rely as much as possible on existing TEI elements, but introduce a new element and a new attribute, to address the specificities of this kind of materials.
Interviews: a precious resource
Figuratively and literally, interview transcriptions are a precious resource. Producing them comes at a high cost: researchers must dedicate a lot of time and money to organize the interviews, travel, speak with the interviewees and transcribe the interviews. They should thus be used and re-used to their fullest potential. Finding a way to properly encoding them will help further qualitative or quantitative analyses by the researcher as well as by other colleagues taking interest in the source. Sharing effectively these resources would allow for comparisons between results obtained by researchers from various disciplines, at different periods and places, or to build larger corpora to obtain new results.
Addressing the reproducibility crisis
Human and social sciences have been targeted by many critics during the “replication crisis” (Ioannidis, 2005 ; Camerer et al., 2018) controversy. Research relying on qualitative analyses are not easily subject to the same reproducibility assessment, but should in many cases allow for “comparative re-production” (Markee, 2017): in a similar context, and following the same principles and questioning, will a new interview lead to results comparable to the ones previously made? Making one’s transcriptions and annotations available would be a way to make this possible. It would also ensure that conclusions drawn from an interview are trusted, as a reviewer, colleague, or reader in general, could access the annotations underlying the researcher’s analyses.
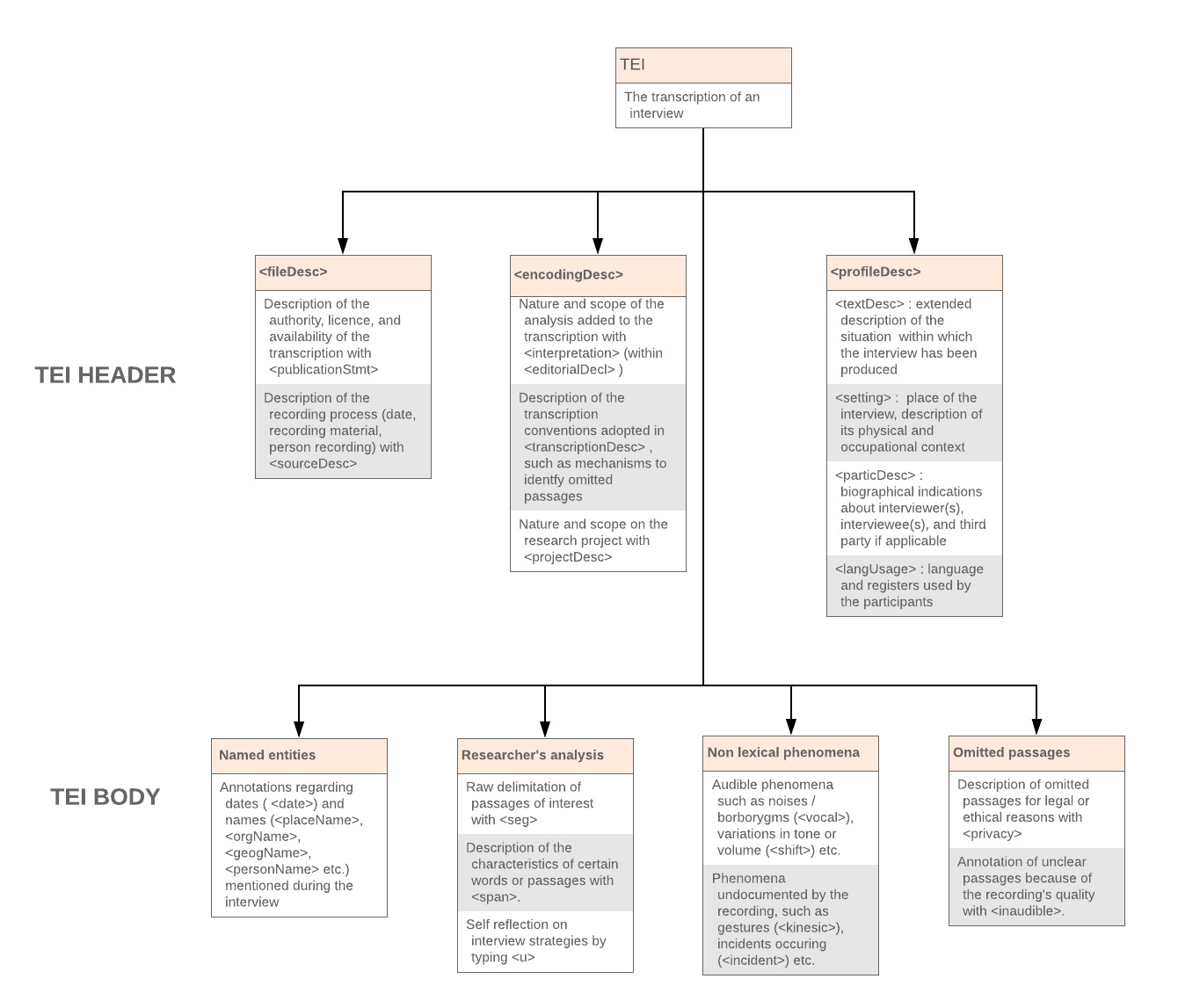
A standard adaptable by each research community
We propose to create an ODD (One Document Does It All), setting out which TEI elements and associated attributes can be used and in which context, and documenting our choices to future users. An ODD also enables to add new elements and attributes. And within a given community, it is possible to agree on an available ODD customization that will ensure the interoperability, shareability and reusability of the TEI files. To create this ODD, we mostly combine the elements and attributes declared by the modules “Transcription of Speech” and “Language Corpora”, and propose to add one new element and one new attribute.
Ethics and respect of privacy
A key concern in sharing qualitative interviews should be the respect of legal constraints and ethics principles. We thus propose the creation of a new element, to annotate passages that could not be freely shared. This element allows for a description of the deleted passage and the reason for its deletion. It is meant to ensure the protection of interviewees, while concealing as little relevant information as possible.
The creation of this new element relies on TEI best practices, and draws on the use of the element
Reflecting on one’s interview practices
The element is used to encode the different parts of speech given by the interviewers and the interviewees, with a “who” attribute to express who is the speaker. But qualitative interviews are not ordinary conversations: they are prepared by a researcher, implementing a strategy to get as much information as possible on a topic of interest. It is thus crucial to encode the researcher’s comments on its own speech (Beaud, 1996): was the question prepared? spontaneous? what was its purpose (changing the subject/knowing more/confirming a previous statement etc.) ? This is why we propose to add a “type” attribute to the list of already existing attributes born by, describing this kind of information.
Annotating the interview: sharing one’s interpretation
In addition to simple content annotations (persons or places cited, dates evoked etc.), our model offers the possibility of sharing one’s interpretations about relevant passages of the transcription.
We propose to use the
 References
References
BEAUD, Stéphane. L'usage de l'entretien en sciences sociales. Plaidoyer pour l'« entretien ethnographique ». Politix. Revue des sciences sociales du politique, 1996, vol. 9, no 35, p. 226-257.
BODARD, Gabriel. EpiDoc: Epigraphic documents in XML for publication and interchange. Latin On Stone: epigraphic research and electronic archives, 2010, p. 101-18.
CADOREL, Sarah, GARCIA, Guillaume, FROMONT, Emilie, et al. beQuali: Une Plateforme d'Archives Numériques en Sciences Sociales. In : Proceedings of the 1st International Conference on Digital Tools & Uses Congress. ACM, 2018. p. 23.
CAMERER, Colin F., DREBER, Anna, HOLZMEISTER, Felix, et al. Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nature Human Behaviour, 2018, vol. 2, no 9, p. 637.
IOANNIDIS, John PA. Why most published research findings are false. PLoS medicine, 2005, vol. 2, no 8, p. e124.
MARKEE, Numa. Are replication studies possible in qualitative second/foreign language classroom research? A call for comparative re-production research. Language Teaching, 2017, vol. 50, no 3, p. 367-383.
MIGUEL, Edward, CAMERER, Colin, CASEY, Katherine, et al. Promoting transparency in social science research. Science, 2014, vol. 343, no 6166, p. 30-31.
The TEI Guidelines, [online]. [Accessed 22 October 2019]. Available from: https://www.tei-c.org/release/doc/tei-p5-doc/en/html/index.html