1. Abstract
The annotation of natural language texts and their use is addressed in many projects in the digital humanities. This not only involves the generation of training data, but also the correction of errors by automatic preprocessing. Nowadays there are many methods for automatic text analysis, and just as many tools (e.g. [10, 13, 3, 9]) which encapsulate them for different natural languages as well as for different programming languages. However, there are relatively few annotation tools (e.g. [6, 13, 4, 11]) for correcting annotations or generating training data. The annotation tools mentioned usually only allow a simple annotation of texts as well as a simple visual annotation support. In addition, the use of knowledge databases, such as Wikipedia, Wikidata, Geonames or similar, are rarely usable. Furthermore, the administration of Corpora, the use of different annotation views, the simultaneous and collaborative annotation of the same texts by different users, the user and group-related granting of access permissions to texts, as well as the dynamic determination of Inter-Annotator-Aggreements, are almost non-existent. However, this limited use of annotation tools shows a gap in the large field of digital humanities that can be closed by the so-called TextAnnotator [8].
The TextAnnotator includes a variety of modules for the annotation of texts, which contains the annotation of argumentative, rhetorical, propositional and temporal structures as well as a module for named entity linking and rapid annotation of named entities (Fig. 2). Especially the modules for annotation of temporal, argumentative and propositional structures are currently unique in web-based annotation tools [2].
TextAnnotator, which allows the annotation of texts as a platform, is divided into a front- and a backend component. The backend is a web service based on WebSockets, which integrates the UIMA Database Interface [1] to manage and use texts. UIMA [5] acts as de facto standard for all NLP tasks and almost all preprocessing tools produce a UIMA output. In order to use raw texts and preprocessed texts with TextAnnotator, they first are automatically converted into the UIMA format with the help of the so-called TextImager [9] and preprocessed.
In addition, texts are made accessible by using the ResourceManager and the AuthorityManager, based on user and group access permissions [7] (Fig. 1). The use of different components allows the flexible and project-related use of one tool for different purposes. Therefore, texts can be placed in a flexible folder structure and edited by different teams. In addition, different views of a document can be created and used depending on the scenario.
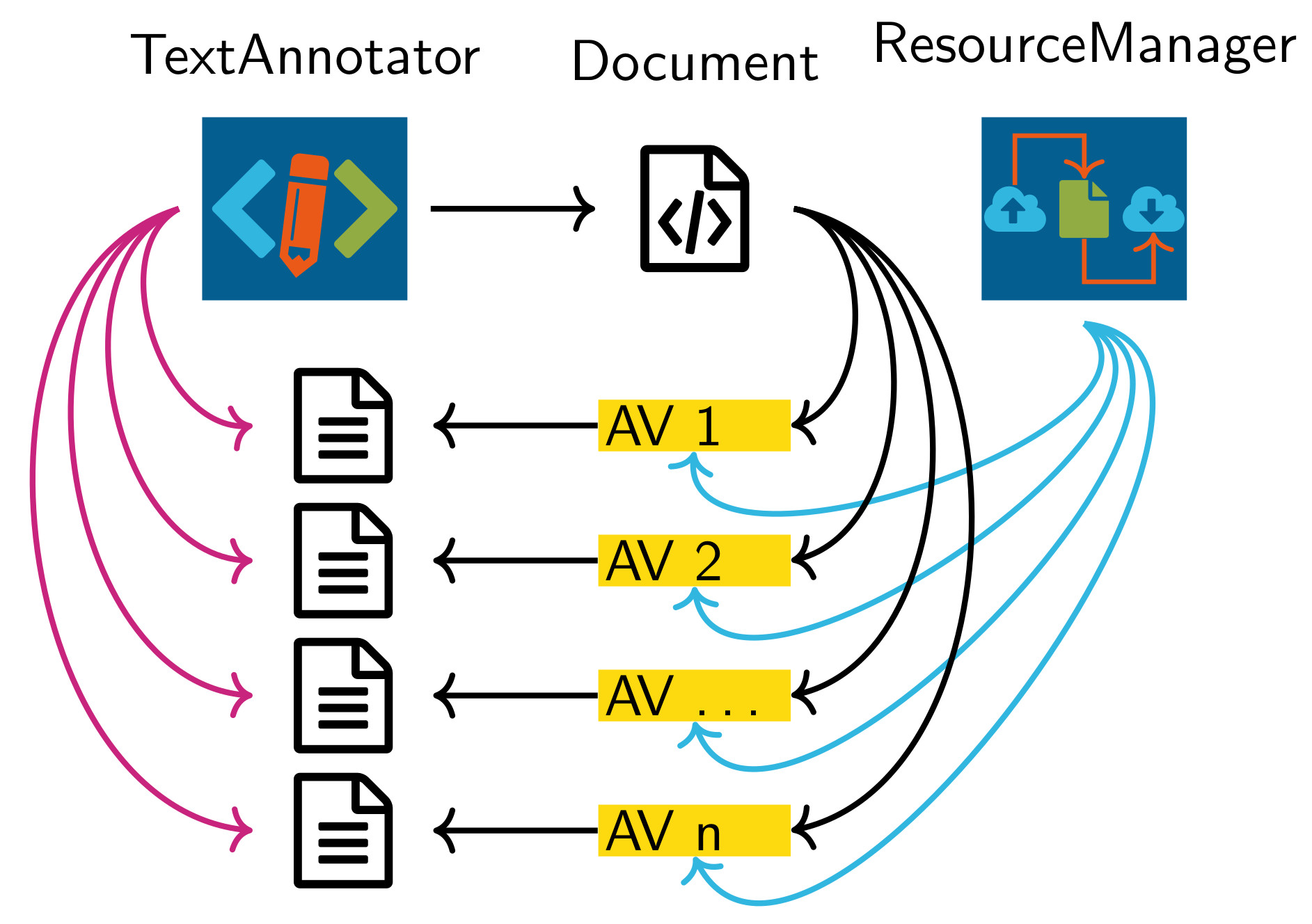 Figure 1: Schematic diagram of the use of annotation views (AV). TextAnnotator has access on documents that contain annotation views which are accessible to users. By this assignment TextAnnotator uses the annotations in the individual views for annotation through implemented tools.
Figure 1: Schematic diagram of the use of annotation views (AV). TextAnnotator has access on documents that contain annotation views which are accessible to users. By this assignment TextAnnotator uses the annotations in the individual views for annotation through implemented tools.
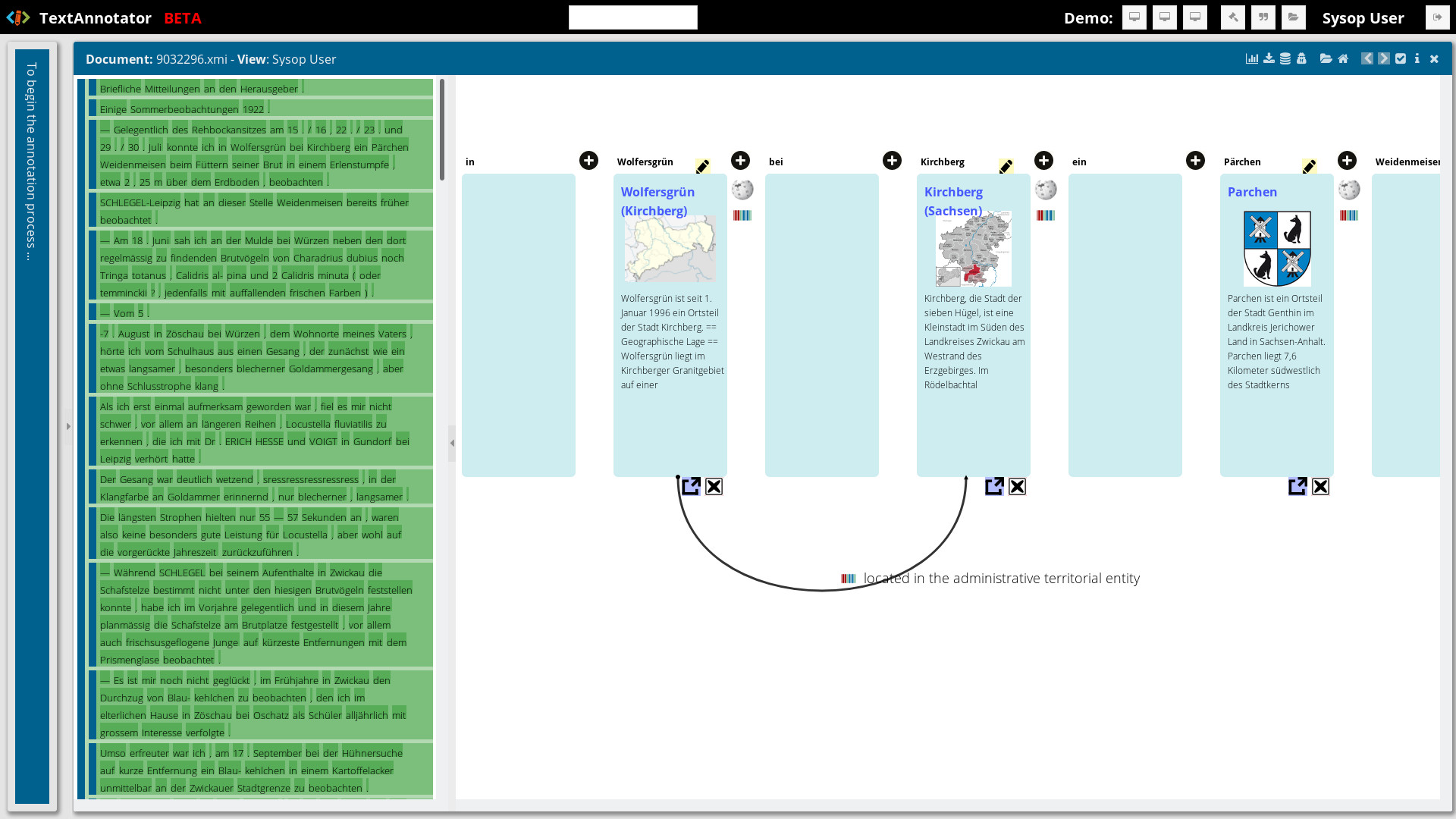 Figure 2: Extract from an annotation session and the use of KnowledgeBaseLinker. The individual tokens can be linked to knowledge resources or the entries can be modified. In this scenario the texts were already automatically preprocessed by the TextImager and the lower line shows an implicit relation which was interpreted based on the Wikidata entries of the respective assignments to the knowledge database Wikipedia.
Figure 2: Extract from an annotation session and the use of KnowledgeBaseLinker. The individual tokens can be linked to knowledge resources or the entries can be modified. In this scenario the texts were already automatically preprocessed by the TextImager and the lower line shows an implicit relation which was interpreted based on the Wikidata entries of the respective assignments to the knowledge database Wikipedia.
Through the use of the frontend component, developed in ExtJS, browser-based access to the texts and the available annotation tools is enabled. Once a document has been opened, access is gained to the annotations stored within annotation views in which these are organized. (Fig. 3). Any annotation view can be assigned with access permissions and by default, each user obtains his or her own user view for every annotated document. In addition, with sufficient access permissions, all annotation views can also be used and curated (Fig. 3). This allows the possibility to calculate an Inter-Annotator-Agreement [12] for a document, which shows an agreement between the annotators. Annotators without sufficient rights cannot display this value so that the annotators do not influence each other.
This contribution is intended to reflect the current state of development of TextAnnotator, demonstrate the possibilities of an instantaneous Inter-Annotator-Agreement and trigger a discussion about further functions for the community.
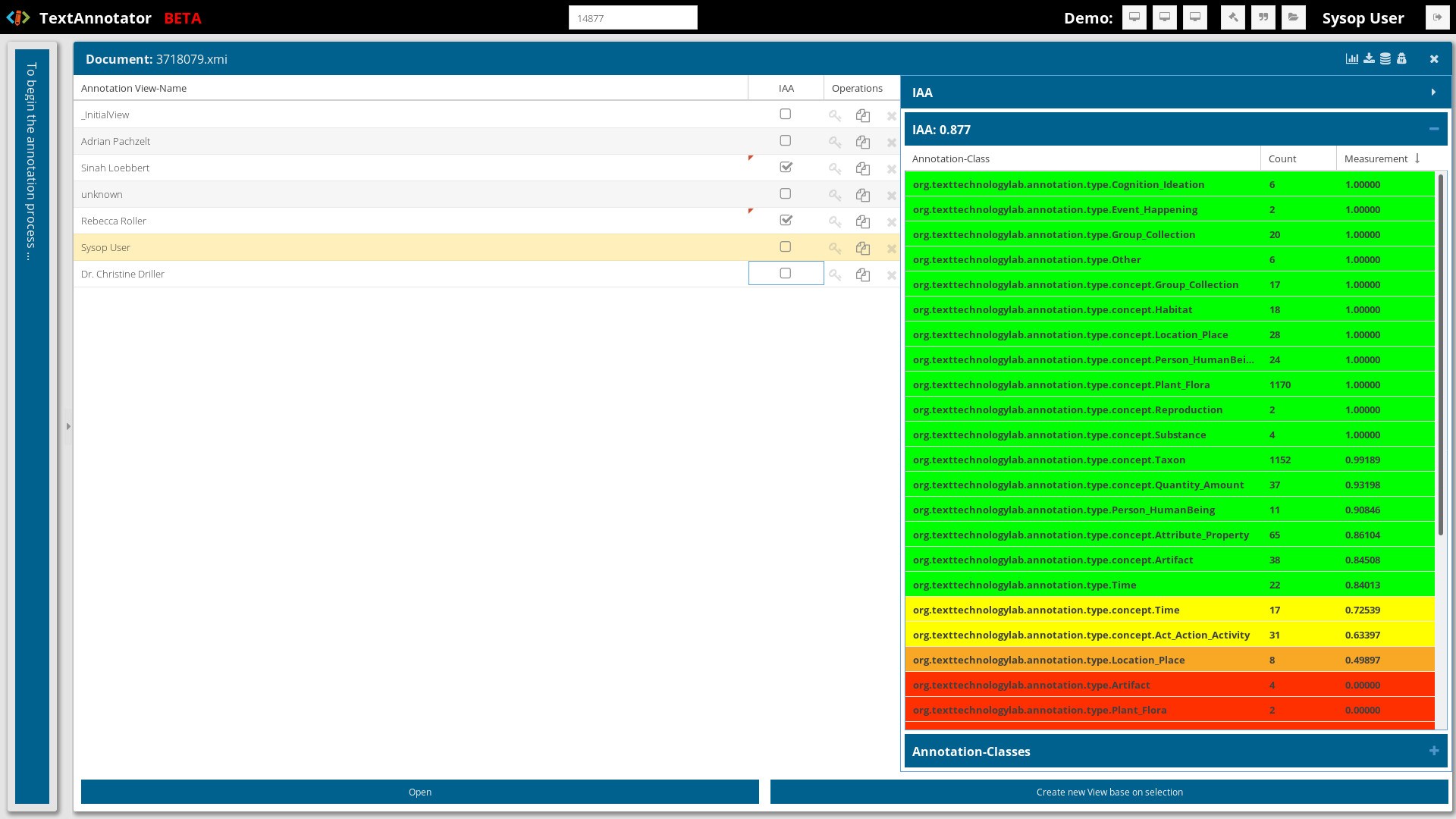 Figure 3: A open document is shown in TextAnnotator. The annotation views are displayed on the left. User views are named with the names of the users other views are annotation views that can be authorized by the user. The IAA value (right) of the document is visualized based on the selected annotation views (left) and the previously selected annotation classes. The agreement of the annotations can be modified arbitrarily (views, classes) and is calculated directly. At the same time, the agreement is highlighted in different colors.
Figure 3: A open document is shown in TextAnnotator. The annotation views are displayed on the left. User views are named with the names of the users other views are annotation views that can be authorized by the user. The IAA value (right) of the document is visualized based on the selected annotation views (left) and the previously selected annotation classes. The agreement of the annotations can be modified arbitrarily (views, classes) and is calculated directly. At the same time, the agreement is highlighted in different colors.
[1] Abrami, Giuseppe and Alexander Mehler (2018). “A UIMA Database Interface for Managing NLP-related Text Annotations”. In: Proc. of LREC. Miyazaki, Japan.
[2] Abrami, Giuseppe, Alexander Mehler, Andy Lücking, Elias Rieb, and Philipp Helfrich (2019). “TextAnnotator: A flexible framework for semantic annotations”. In: Proc. of ISA-15. Gothenburg, Sweden.
[3] Castilho, Richard Eckart de and Iryna Gurevych (2014). “A broad-coverage collection of portable NLP components for building shareable analysis pipelines”. In: Proc. of OIAF4HLT. Dublin, Ireland, pp. 1–11
[4] Castilho, Richard Eckart de, Éva Mújdricza-Maydt, Seid Muhie Yimam, Silvana Hartmann, Iryna Gurevych, Anette Frank, and Chris Biemann (2016). “A Web-based Tool for the Integrated Annotation of Semantic and Syntactic Structures”. In: Proc. of COLING, Osaka, Japan. pp. 76–84.
[5] Ferrucci, David, Adam Lally, Karin Verspoor, and Eric Nyberg (2009). Unstructured Information Management Architecture (UIMA) Version 1.0. OASIS Standard.
[6] Gerdes, Kim (2013). “Collaborative Dependency Annotation”. In: Proc. of DepLing. Prague, Czech Republic, pp. 88–97
[7] Gleim, Rüdiger, Alexander Mehler, and Alexandra Ernst (2012). “SOA implementation of the eHumanities Desktop”. In: Proc. of Workshop on Service-oriented Architectures (SOAs) for the Humanities: Solutions and Impacts, Digital Humanities, Hamburg, Germany.
[8] Helfrich, Philipp, Elias Rieb, Giuseppe Abrami, Andy Lücking, and Alexander Mehler (2018). “TreeAnnotator: Versatile Visual Annotation of Hierarchical Text Relations”. In: Proc. LREC. Miyazaki, Japan.
[9] Hemati, Wahed, Tolga Uslu, and Alexander Mehler (2016). “TextImager: a Distributed UIMA-based System for NLP”. In: Proc. of the COLING System Demonstrations. FedCSIS. Osaka, Japan.
[10] Hinrichs, Erhard, Marie Hinrichs, and Thomas Zastrow (2010). “WebLicht: Web-based LRT Services for German”. In: Proc. of ACL 2010 System Demonstrations. ACLDemos. Uppsala, Sweden, pp. 25–29
[11] Klie, Jan-Christoph, Michael Bugert, Beto Boullosa, Richard Eckart de Castilho, and Iryna Gurevych (2018). “The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation”. In: Proc. COLING System Demonstrations. ACL, pp. 5–9
[12] Meyer, Christian M., Margot Mieskes, Christian Stab, and Iryna Gurevych (2014). “DKPro Agreement: An Open-Source Java Library for Measuring Inter-Rater Agreement”. In: Proc. of COLING System Demonstrations. Dublin, Ireland, pp. 105–109.
[13] Stenetorp, Pontus, Sampo Pyysalo, Goran Topi?, Tomoko Ohta, Sophia Ananiadou, and Jun’ichi Tsujii (2012). “BRAT: A Web-based Tool for NLP-assisted Text Annotation”. In: Proc. of EACL. Avignon, France, pp. 102–107.