1. Abstract
Introduction
Digitised newspapers have become an increasingly prominent resource for scholars in the Digital Humanities (Bingham 2010; Smits, 2014). These digital collections provide insights into contemporaneous reporting on a wide range of events, from disruptive, historical turning points, to the banal, mundane aspects of everyday life. While rich in content, digitised newspapers by themselves often lack the essential metadata researchers need to interrogate these collections rigorously.
The British Newspaper Archive, for example, boasts that it contains more than 37 million pages, which, although amounting to a large number of words, constitutes only around 6% of the estimated total of newspaper pages. Establishing how the digital “sample” relates to the total “population” of newspapers has been difficult if not impossible. Similar challenges have been found when working with digital book collections (Francois 2013).
In this paper, we demonstrate how contextualizing newspapers from the British Newspaper Archive allows scholars to understand the contours of this corpus and to critically interrogate the digital archive for potential biases. Below, we introduce our sources, then explain how we digitized, encoded and linked them, and conclude with some preliminary results that show what type of research could emanate from this work.
The Newspaper Press Directories
To investigate the contours of the Victorian press, we set out to digitize the “Newspaper Press Directory”, a contemporaneous record that catalogued periodicals circulating in Britain. Created by Charles Mitchell in 1846, the Directory was published as an annual guide for advertisers, helping them to find relevant audiences. In 1861, Mitchell’s Directory was recognized by the Post Office as an authoritative list of the London and Provincial newspapers (Brake 2015; Gliserman, 1969).

Figure 1: Example from Mitchell’s Press Directory, 1857
Figure 1 shows a description of the “Gloucestershire Chronicle” taken from Mitchell’s 1857 edition. The Directory systematically lists the political leaning, price and day(s) of publication, which allows us to profile newspapers, i.e. locate them geographically as well as socially (i.e. places of circulation and audience). Mitchell's attempted to provide a "dignified" account of the press, was not unproblematic. As (O'Malley, 2015) points out: the Directory didn't simply reflect the Victorian press but was also an actor that shaped the newspaper landscape.
Nonetheless, the directories provide a useful entry point to organizing the 19th century newspapers. We, therefore, attempted to contextualize the British Newspaper Archive by linking this collection to information derived from the Directory. Initially, we focussed on two counties (Lancashire and Dorset) for six different years (1847, 1857, 1860, 1867, 1877, 1888, 1898 and 1908).
We selected these two counties because this research takes place in Living with Machines, a larger project focussed on the lived experience of the industrial revolution. The counties experienced different chronologies with respect to their industrialisation: Dorset remained rural for much of the nineteenth century, while Lancashire industrialised early.
Methodologically, the biggest challenge lay in parsing and encoding these documents automatically. Mitchell’s Directory adheres to a rather intricate and shifting typographical layout, with many different fonts and transitions between cursive and bold type. This, unfortunately, significantly deteriorated the OCR quality. To process these documents we trained two different models: a page segmentation model that splits the directory into separate entries (each describing one newspaper) and a “semantic” model that overlays the individual entries with more refined annotations (title, price, political leaning, but also named entities such as Location, Person and Institution). The mock example below shows the input and output of this process.
Example Input: [...] Proprietor—Henry Smith, general printer, as'the representative of Trustees. (Advertisement, p. 104.)? NEAL’S CAMBRIDGE GAZETTE. Monthly,Price U/. IMeiifr&il.—Established March, 1855. Circulates in Cambridge and its district. This is a union of the local intelligence of the district, with general news and miscellanies. Proprietor—Jonathan Neal.? CAH.TEBBI1 BY__________{Kent.)?
Example Output:
To train the models, we first manually labelled a random sample with a tool called INCEpTION (Klie et al. 2018). Structural parsing is roughly equal to page segmentation, which is reflected in the tag set (Table 1). Words that describe a newspaper (as in Figure 1) are classified as “Newspaper” (with “Start” and “Stop” indicating the boundaries). As the directories are organized geographically (by district), we tagged a new location as “District-Header” and its accompanying text as “District-Description”.
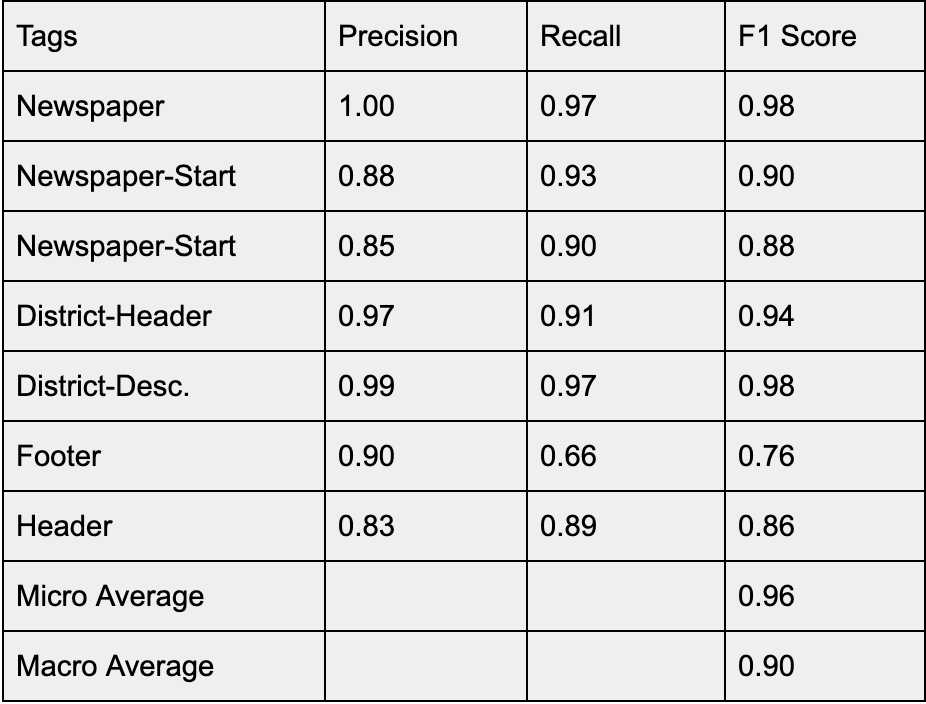
Figure 2: Table 1: Results of structural parsing
We applied Conditional Random Fields classifier to segment pages. We vectorized the target and neighbouring words using (among others) the following features: use of punctuation and capitals, part-of-speech, named-entity type, etc. We treated word-window, number of iterations and regularization terms as hyper-parameters which we selected based on a grid search. This resulted in a micro f-score of 0.96, training on a corpus of 40 pages and testing on a set of 10 pages.
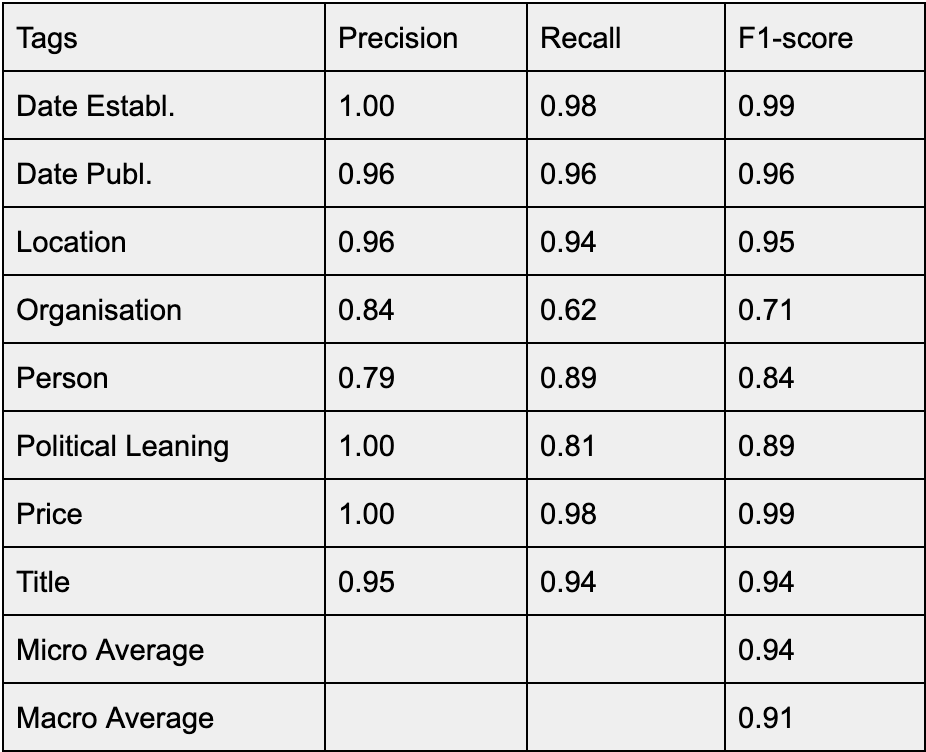
Figure 3: Table 2: Results semantic parsing
The semantic parser takes a segmented page as input, and establishes the “function” of each word in the document, identifying the recurrent elements of the Directory, such as title, price, and political, to which we added other basic named-entities such as Location, Person and Institution.
We followed the procedure developed by (Akbik, Blythe, and Vollgraf 2018) which applies contextual string embeddings to sequence labelling. More concretely, we used pre-trained character level Flair embeddings (both the backward and forward pass trained on a corpus of 1 billion words) to encode the tokens, which are subsequently forwarded to a Bi-LSTM. In total, we annotated 240 entries, which we split into a training (166), development (36) and test set (36).
Table 2 lists the f-scores obtained after training for 20 epochs. Currently, the tagger fails to accurately identify Organisation-type entities from the descriptions, but it does a reasonable job on other entities such as Locations and Persons. It accurately detects titles and prices but performs less well on the tokens which signal political leaning (this could be due to the many OCR errors).
After training both models we applied them to the digitised Directories. Initially, we focussed only on the section that lists provincial newspapers (given the counties of interest, we excluded London), which resulted in a set of almost 7000 newspaper profiles. Figure 4 shows the number of provincial titles over time.
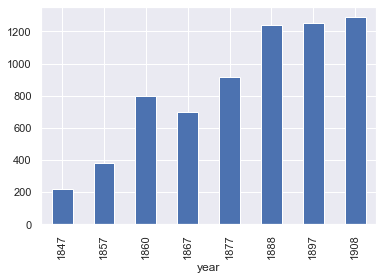
Figure 4: Number of provincial newspaper titles over time
Potential Research Outcomes
Below we discuss briefly the types of research questions we can answer by contextualizing the Victorian newspaper data. Firstly, we analysed the extent to which digitized newspapers are representative of the broader landscape with respect to their political composition.
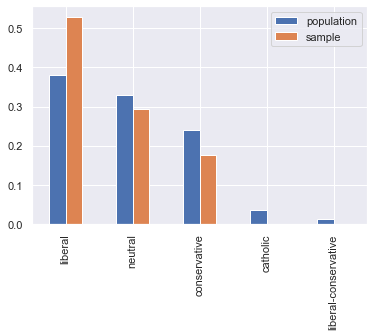
Figure 5: Distribution of political leaning in sample and population.
Figure 5 directly compares the digital sample to the newspaper population, suggesting that the distribution between them differs substantially. The Liberal press, in particular, is overrepresented compared to Neutral and Conservative newspapers (using the categorization applied by the Directory itself). Moreover, some perspectives are simply excluded, such as Catholic voices.
Future research needs to explore the impact of these biases, but preliminary experiments already hint at the possibly distorting effects on potential research outcomes and interpretations.
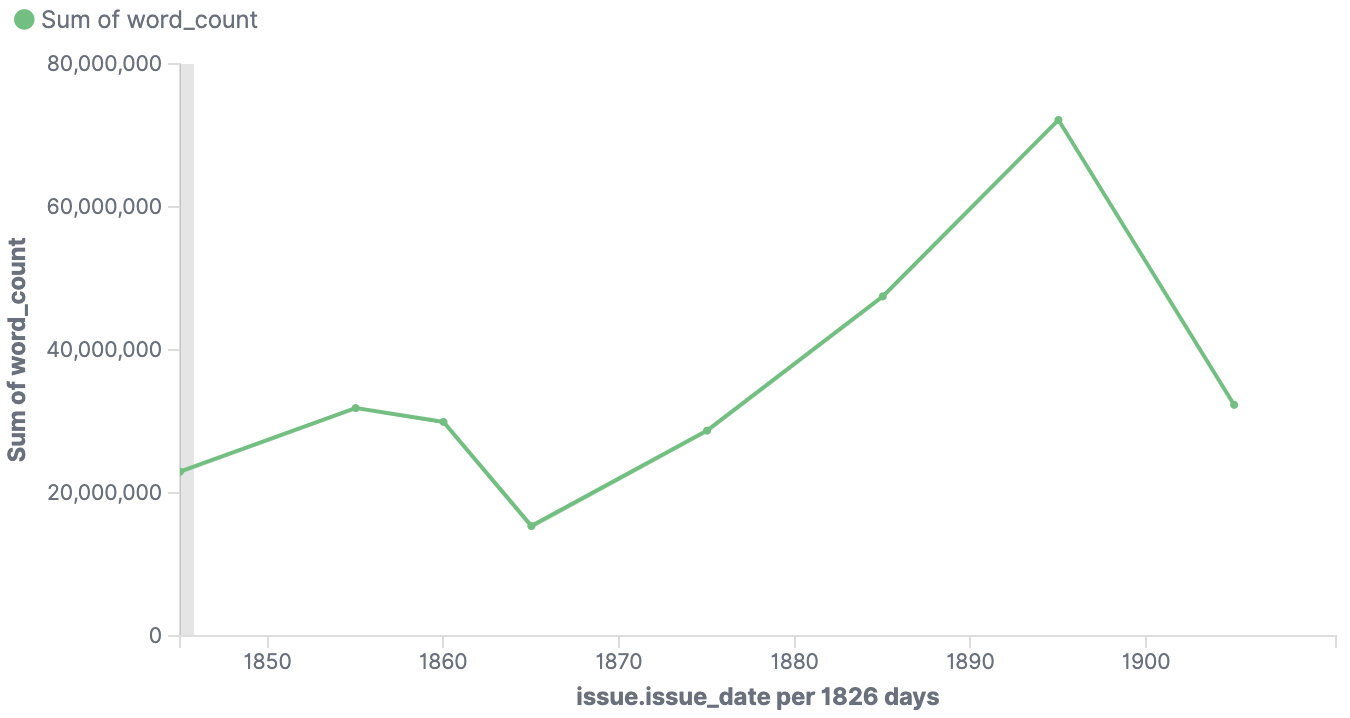
Figure 6: Number of words for articles circulating in Dorset
Figure 6 shows the word count for all the newspapers that circulated in Dorset. What this timeline fails to convey, however, is a political transition from Conservative to Liberal--which happens in the background, and only becomes visible after integrating information from the Directory (figure 7).
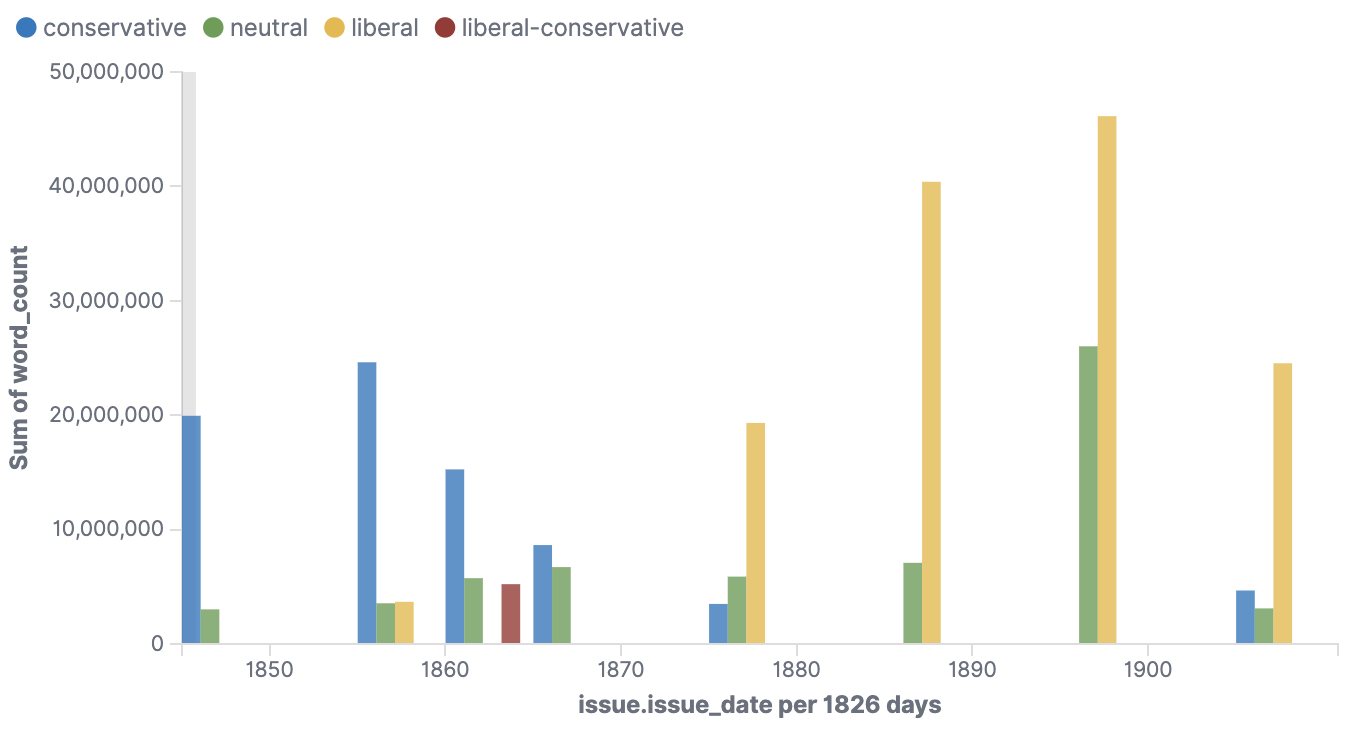
Figure 7: Number of words by political party for articles circulating in Dorset
Besides explicating the political dimension, the enriched dataset can provide a more holistic view on the geographic circulation of newspaper data as shown in Figure 8, which compares places of publication with circulation.
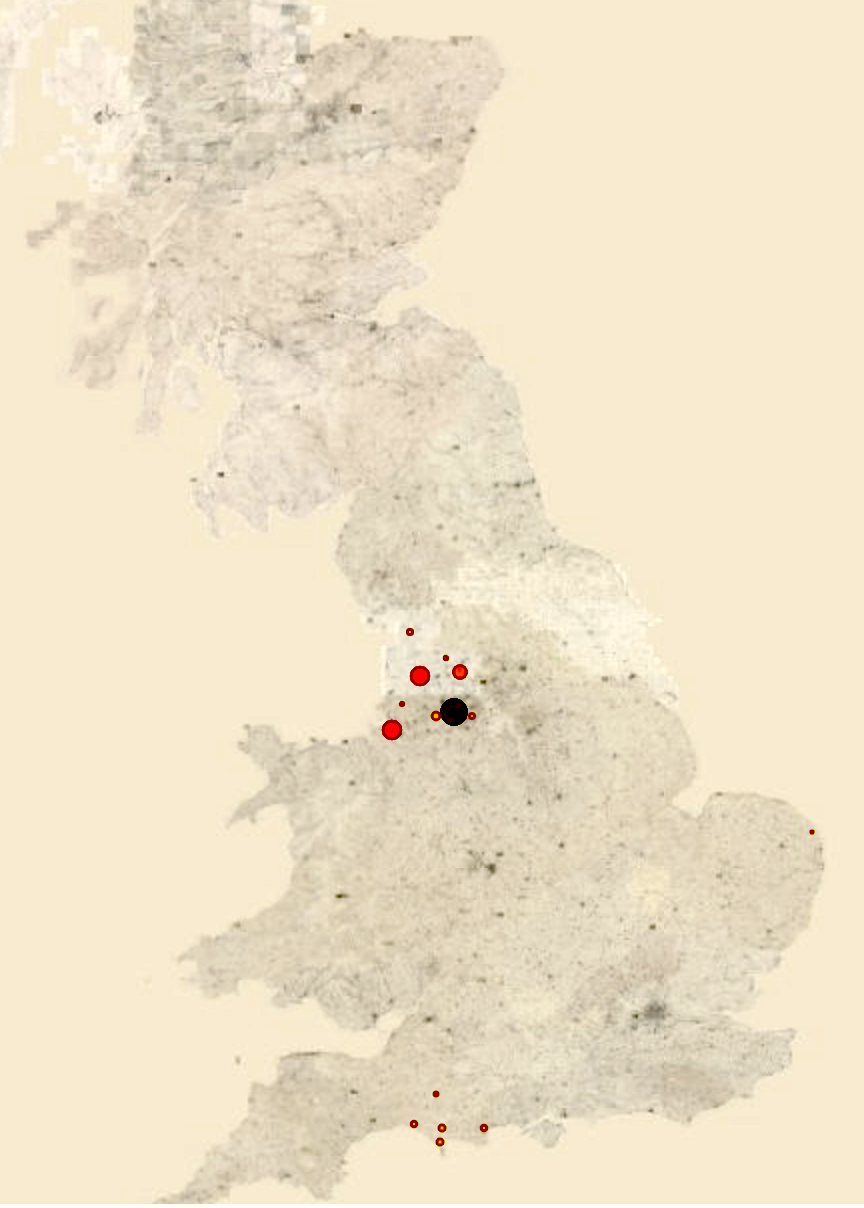
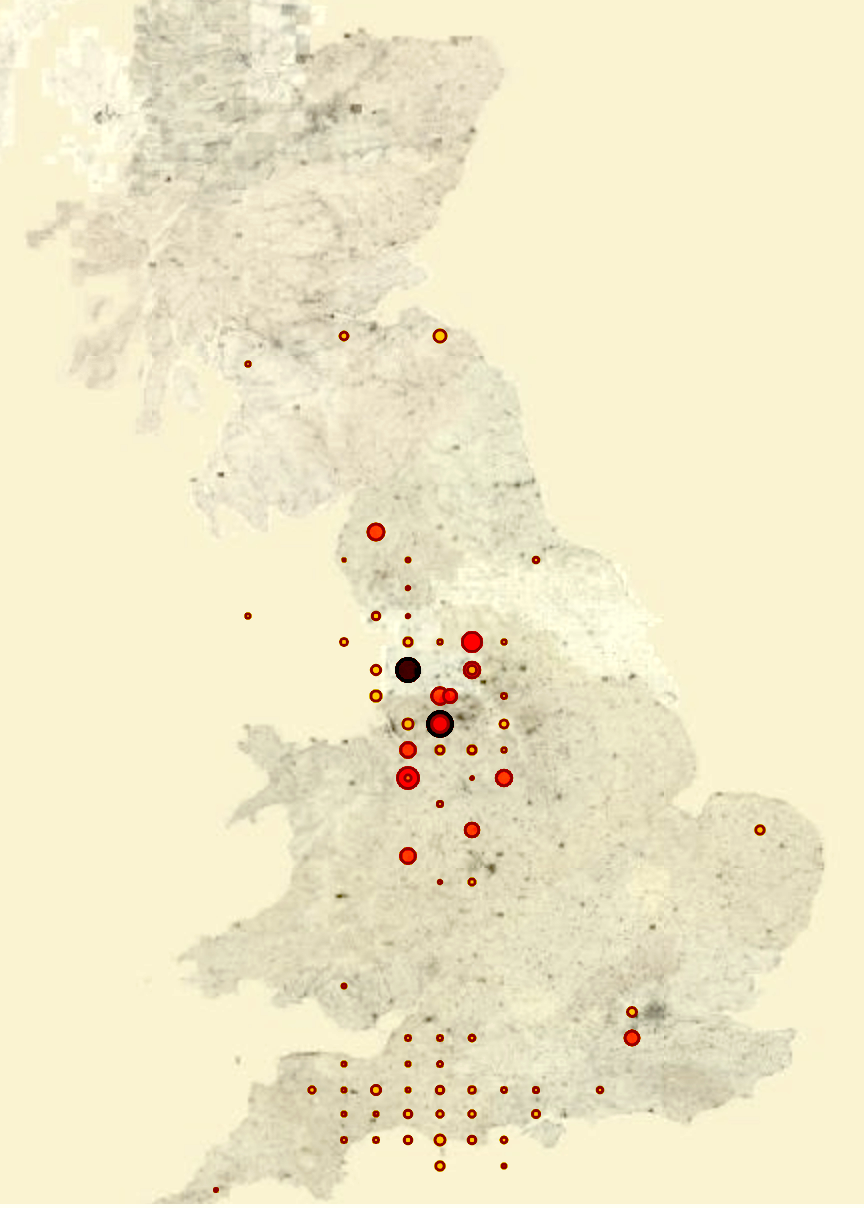
Figure 8: Number of articles by place of publication (left) and place of circulation (right) We thank the National Library of Scotland for access to their tileserver. Map images courtesy National Library of Scotland.
* Code will be available in the Living with Machines github organization: https://github.com/Living-with-Machines
References
Akbik, Alan, Duncan Blythe, and Roland Vollgraf. 2018. ‘Contextual String Embeddings for Sequence Labeling’. In Proceedings of the 27th International Conference on Computational Linguistics, 1638–49.
Bingham, Adrian. 2010. ‘“The Digitization of Newspaper Archives: Opportunities and Challenges for Historians”’. Twentieth Century British History 21 (2): 225–31. https://doi.org/10.1093/tcbh/hwq007.
Brake, Laurel. 2015. ‘Nineteenth-Century Newspaper Press Directories: The National Gallery of the British Press’. Victorian Periodicals Review 48 (4): 569–90. https://doi.org/10.1353/vpr.2015.0055.
Francois, Pieter. 2013. ‘The Sample Generator - Part 1: Origins’. British Library Digital Scholarship Blog. 2013. https://blogs.bl.uk/digital-scholarship/2013/11/the-sample-generator-part-1-origins.html.
Klie, Jan-Christoph, Michael Bugert, Beto Boullosa, Richard Eckart de Castilho, and Iryna Gurevych. 2018. ‘The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation’. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations, 5–9. Association for Computational Linguistics. http://tubiblio.ulb.tu-darmstadt.de/106270/.
O'Malley, Tom. 'Mitchell's Newspaper Press Directory and the Late Victorian and Early Twentieth-Century Press.' Victorian Periodicals Review 48, no. 4 (2015): 591-606.
Smits, Thomas. 2014. ‘TS Tools: Problems and Possibilities of Digital Newspaper and Periodical Archives’, 8.