1. Abstract
We evaluate methods for segmenting short stories from in-copyright science fiction anthologies that are only accessible through page-level word count data. Compared to the novel, short fiction is understudied in the digital humanities. This gap can be attributed to both the novel’s role as the more popular (and prestigious) publication form in fiction and the added cost of separating collections into their constituent parts. While it is easier to study novels, novels are an insufficient proxy for studying the greater landscape of fiction. Many voices are lost if we limit our focus to novels. Moreover, the formation of science fiction as a distinct genre in English is directly tied to the rise of pulp magazines: a medium that focused on short fiction. Studying science fiction anthologies will allow us to find subtle trends in the history of the genre, and make quantitative comparisons between the structure of short stories and novels.
But accessing short fiction is difficult due to copyright, collection practices, and printing formats. Much of the work in science fiction falls into the mid-to-late 20th-century "dark zone" where it is too new to be public domain but too old to exist in born-digital format. The existence of large-scale repositories of digitized library collections, such as HathiTrust, offer the possibility to begin analyzing short fiction through non-expressive data views. The problem, then, is segmentation. The fundamental unit of HathiTrust is the volume, and little to no sub-volume structure is recorded in either HathiTrust metadata or the catalog records of source libraries. We therefore focus on identifying the boundaries of stories from non-expressive page-level data.
Data. We identify 690 volumes within the HathiTrust Research Center’s Extracted Features Dataset (EF) (Capitanu et al. 2016) representing 529 science fiction anthologies published between 1940 and 2009. For each page in a volume, EF data segments headers, body text, and footers, and provides the text and part-of-speech of every word token in those segments, but does not preserve order within segments. For example, a header page of Nalo Hopkinson's "A Habit of Waste" within Women of Other Worlds: Excursions Through Science Fiction and Feminism is represented as [Hopkinson_NNP \_JJ habit_NN waste_NN of_IN Nalo_NNP]. Note this data can include OCR errors, such as "\" instead of "A".
To validate our approach we also collect metadata from The Internet Speculative Fiction Database (ISFDB).1 For anthologies, ISFDB typically provides the (edition-level) starting page for each short fiction entry, along with its title, author, length type (e.g. novella), and a list of other anthologies it has been published in, allowing us to link copies of the same story in different anthologies. We created a training set linking 68 EF volumes to their ISFDB metadata at the page level. This volume set represents 34 anthologies: two per anthology.
Segmentation. We treat the segmentation task as a supervised classification problem, in which the goal is to predict whether a given page is the beginning of a new segment. We evaluate a number of features for segmenting stories. For simplicity, we assume that every page corresponds to only one story. A reasonable starting point for identifying story transitions is to identify pages with unusually few tokens.
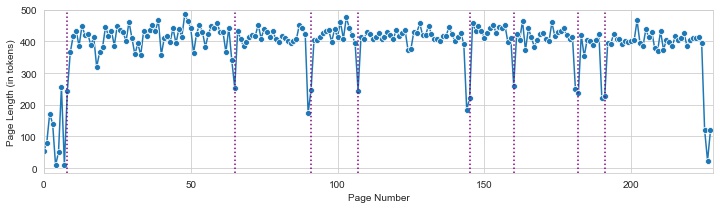
Figure 1: Page lengths can reflect actual transitions (vertical lines).
We note that there are often pairs of unusually short pages at segment boundaries, where one story ends mid-page and a new one begins in the middle of the next page. Since the absolute number of words per page varies from volume to volume, we normalize the length of each page to a number of standard deviations from the mean for the volume. For each page we also provide the deviation of the previous and following pages.
Headers and footers might also be helpful since they can contain short fiction titles and authors. We find that headers are much more common for science fiction anthologies than footers. There are 619 volumes with many headers, but only 20 with many footers. To allow for OCR errors, instead of exact string matches we measure the Jaccard similarity of character trigrams between headers. As headers often alternate, we record the maximum similarity of the five previous and subsequent pages and the maximum of the five subsequent pages. If boundary information is in the header, it becomes much easier to verify transitions given word statistics since these segments are very short.
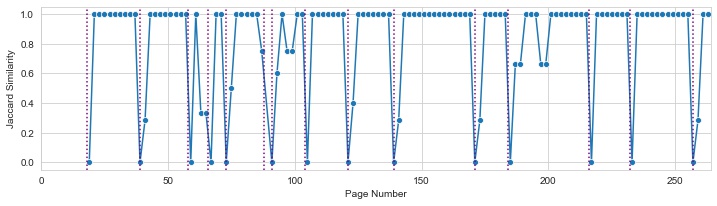
Figure 2: Similarity of odd page headers can also mark transitions, but sometimes they're absent.
Analysis. In addition to raw features from page length and header similarity, we add a small set of pairwise product features to represent interactions between variables: length * prev_length, length * next_length, and the product of those two products; prev_header_similarity * next_header_similarity. For analysis, we use 34 labeled volumes representing distinct anthologies. For 20 cross-validation splits we hold out 20% of these volumes for evaluation. Using all features, we find that 58% +/- 11.8 of labeled boundaries match a predicted boundary. 63% +/- 10.9 of labeled boundaries have a predicted boundary within one page. Boundary predictions are conservative, with 93% +/- 3.7 of predictions within one page of a labeled boundary. The difficulty of the task varies between volumes, often because of the quality of headers, OCR problems, and idiosyncratic boundaries. Without product features, performance drops to 37% exact, 44% of labels within one page of a prediction, and 79% of predictions within one page of a label. With only raw length features these numbers are 14%, 17%, and 67%; header features alone are precise but limited, at 21%, 26%, and 78%. Results for the other 34 labeled volumes are similar.
Applying the full model trained with all labeled volumes to the complete set of 690 anthologies results in just over 10,000 predicted segments. Not all of these correspond to stories, but even with this noisy sample we have substantially improved our ability to access short-form science fiction.
Future Work. All of our current metrics rely on the formatting of pages. We predict that the content of stories may also have clues, with the names of characters and settings changing between stories. Although we expect these methods to be less successful, they will be useful indicators for when an identified segment needs to be further divided and will work for a wider range of publishing formats. The fact that product features did so well indicates that structured prediction models for sequences and multi-layer neural networks might improve performance further.
Notes.
1. https://www.isfdb.org
References.
Capitanu, Boris, Ted Underwood, Peter Organisciak, Timothy Cole, Maria Janina Sarol, and J. Stephen Downie (2016). The HathiTrust Research Center Extracted Feature Dataset (1.0) [Dataset]. HathiTrust Research Center, http://dx.doi.org/10.13012/J8X63JT3.