1. Abstract
Abstract
We perform several experiments regarding the interaction of local syntax with meter and rhythm in poetry and prose. To that end, we annotate 3600 lines of German poetry for syllable stress, foot boundaries, caesuras, and the main accents in a line, to then train Conditional Random Fields to predict these features and also part-of speech. With these models, we first determine a stress accent ratio, i.e., the likelihood that a particular part-of-speech is stressed or unstressed in a larger poetry corpus, which then allows us to establish a stress hierarchy (nouns are usually stressed, but determiners seldom so). Second, we determine the context dependence of these stress ratios by investigating when and how strongly stress ambiguous words (like adverbs) change their stress ratio based on their local context. Third, we classify poetry against prose, both on a syntactic and a rhythmic level, to then interpret feature weights. Finally, we look at the interaction of a simple form of enjambement with part-of-speech and verse measures.
1 Introduction
The verbal rendering of thought requires the choice of appropriate lexical items and their ordering according to the rules of syntax. Syntax, however, does not fully determine word order: speakers and writers can often choose among possible syntactic constructions when formulating their message. Semantic, pragmatic, as well as phonological constraints are known to affect wording. In spontaneous language production, semantic constraints presumably control sentence structure more immediately and to a stronger degree than phonological constraints. This follows from the logical directionality of language production, in which the semantic content of the message governs lexical choice and the assignment of syntactic function; phonology and rhythm can exert their role and endow the structure with sound only once a syntactic scaffold has been constructed (Levelt, 1993).
In contrast, the diction of poetry can be strongly governed by prosodic regularities that can be used not only for aesthetic effect by endowing a musical quality (Menninghaus et al., 2017; Menninghaus et al., 2018), but also through deliberate deviation from a regular form, consequently highlighting the relevant utterance (Attridge, 2014; Blohm and Menninghaus, 2018). In order to enforce a particular prosodic form may thus affect the choice of syntactic constructions and the order of constituents within a sentence, attesting the influence of prosody on syntax in lyric poetry.
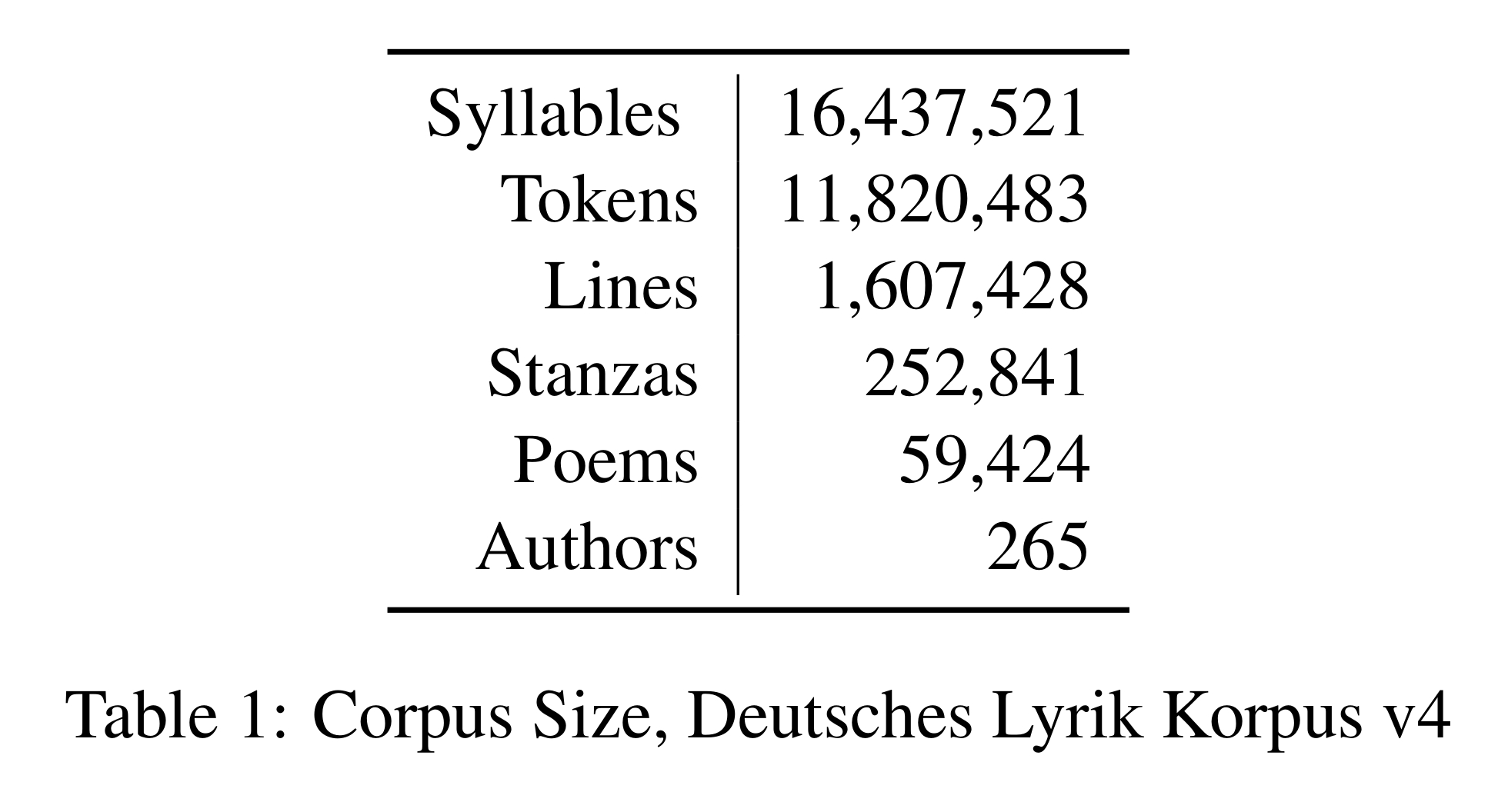
To analyze the interaction of syntax with meter and rhythm at scale, we make use of the German poetry corpus in version 4 (Haider and Eger, 2019), containing the poetry of Textgrid (textgrid.de) and the German text archive (DTA: deutschestextarchiv.de). The corpus contains 59k poems with over 1.6M lines. It is available at github.com/tnhaider/DLK. See Table 1 for a size overview.
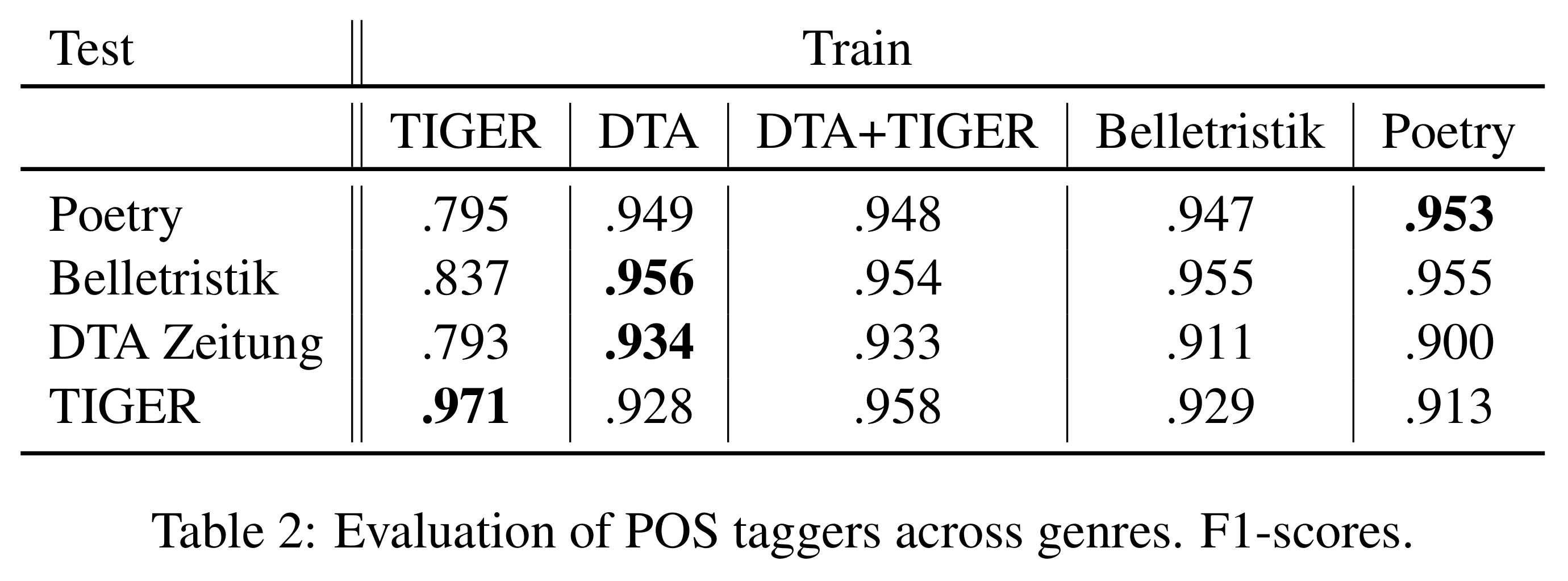
We train Conditional Random Fields (CRF) with the sklearn crf-suite to automatically annotate the whole German Poetry corpus (1.6 million lines) for part-of-speech (POS), binary meter (BM), and natural speech rhythm with three levels of syllable prominence (TR). To that end, two students of linguistics / literature manually annotated 3600 lines of school canon poetry for binary meter (BM) and ternary rhythm (TR). For POS, we rely on gold annotation from DTA and the TIGER Corpus, according to the STTS tagset. We train and test across several genres to determine the most robust POS model for our purposes. See Table 2 for an overview of the POS models. We find that training on TIGER is not robust to tag across domains, falling to around .80 F1-score when testing against different genres from DTA. Training on the whole DTA or on Belletristik (fiction/literature) is however sufficient to tag poetry or fiction. The results suggest that this model degradation across domains is mainly attributable to the curious historical orthography in DTA, and to a lesser extent due to local syntactic inversions that likely occur because of the strict metrical form (Gopidi and Alam, 2019).
See example (1) for an annotated line of poetry with BM and TR. BM includes binary syllable prominence (+/-) and foot boundaries ( ). TR segments the verse into rhythmic groups at caesuras (:) and in these segments allows for main accents (2), side accents (1), and no accent (0). The example line illustrates a regular iambic pentameter, a caesura at the comma, and two rhythmic groups of the same length but with different form.
(1) met="-+|-+|-+|-+|-+|" rhythm="01020:20102:"
Ge-DUCK-te H¨UT-ten, PFA-de WIRR ver-STREUT,
TR differs from BM such that TR operates top-down from rhythmic segments to find natural speech rhythm, while BM adheres more to a conventional metrical poetry analysis and starts bottom-up from syllable prominence. Annotators largely followed an intuitive notion of rhythm, and incorporated philological knowledge to consider the (schema) consistency of the poem. They were also instructed to prefer longer feet over short ones (where applicable).
Our inter-annotator agreement is substantial. Five poems were annotated by two annotators, and calculated on each syllable, Cohen κ for metric syllables was at .95, and .84 for rhythmic syllables. For the latter, mainly side accents (1) were confused. Caesuras alone had a kappa of .92. Metric feet were more challenging and will not be discussed here, as there are multiple reasons why feet boundaries can be ambiguous.
The CRF models are trained on syllabified lines without punctuation. The features contain the syllable token, including two syllables to the left and the right, and also orthographic features like capitalization. During training, we also allow it to see the surrounding labels (which are not available during testing). We achieve 95% F1-score for POS and BM on syllable level, while TR (including caesuras) still performs well with 83% F1-score. The confusion of the TR model is similar to humans who also confuse main and side accents.
2 Experiments
2.1 Stress Hierarchy
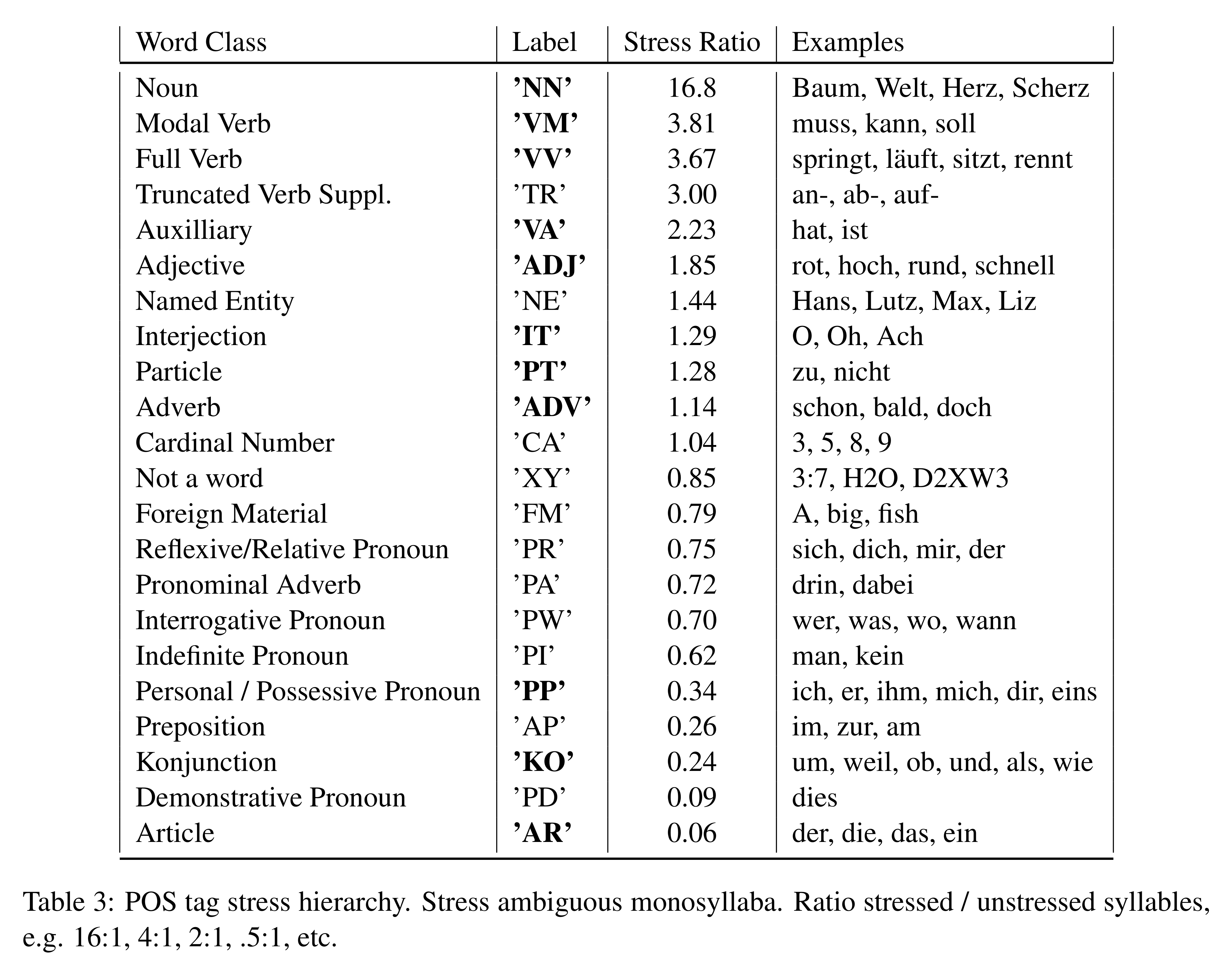
To determine the likelihood of a word belonging to a certain POS class being stressed or unstressed, we iterate over our set of 1.6 million lines of poetry, using the CRF models to annotate the Corpus for BM and POS. For our experiments, we simplify the tagset. We then count how often a POS tag falls into a metrically stressed or unstressed syllable. Multisyllabic words have mostly lexically fixed stress patterns, e.g., German words with two syllables are usually trochaic, where the first syllable is stressed and the second syllable is unstressed (the notable exceptions being alTAR and naTUR). For words with three syllables, we found that nouns are more likely to follow the (+,-,+) pattern, while verbs prefer (-,+,-). In the following, we only measure the prominence of monosyllabic words, as these display the most ambiguity, as the stress of monosyllabic words is mostly determined by their context.
Anttila et al. (2018) also determined a stress hierarchy, only for sentential stress in political speeches and not for syllables in poetic lines. They are able to establish a stress hierarchy of POS-tags, such that NOUN > ADJ > VERB > FUNC. This shows that functions words (FUNC, e.g. KONJ, ART, APPR, etc) are seldom the main accent of a sentence, while nouns are usually stressed. Based on our corpus, we determined the following hierarchy for monosyllabic word forms:
NOUN > V ERB modal > V ERB full > ADJ > ADV > FUNC.
This hierarchy reflects the ratio r of stressed to unstressed syllables, normalized to 1. The ranking of all POS with their respective r can be seen in Table 3. When a POS class is equally likely to be stressed or unstressed, r will be 1.0, or 1:1. For a ratio r = 16.0 (16:1), the word class is 16 times more likely to be stressed. We found it striking that modal verbs are stressed so strongly (3.8:1). We also determined that monosyllabic verbs are more likely in metrically strong positions than monosyllabic adjectives, which differs from what Anttila et al. (2018) found. However, the ends of the hierarchy (nouns and function words) are the same. Plus, this study does not distinguish between adverbs and adjectives and also have only one verb class.
Related work of Nenkova et al. (2007) determined the strength of the POS signal for word accent prediction and developed the ’accent ratio’ measure that determines the likelihood of a wordform (not POS) to be prominent or not, and showed hierarchies for word stress, while (Greene et al., 2010) looked at monosyllabic word. To the best of our knowledge, a dedicated hierarchy concerning a part-of-speech stress ratio has not been constructed yet.
2.2 Context Stress Ambiguity
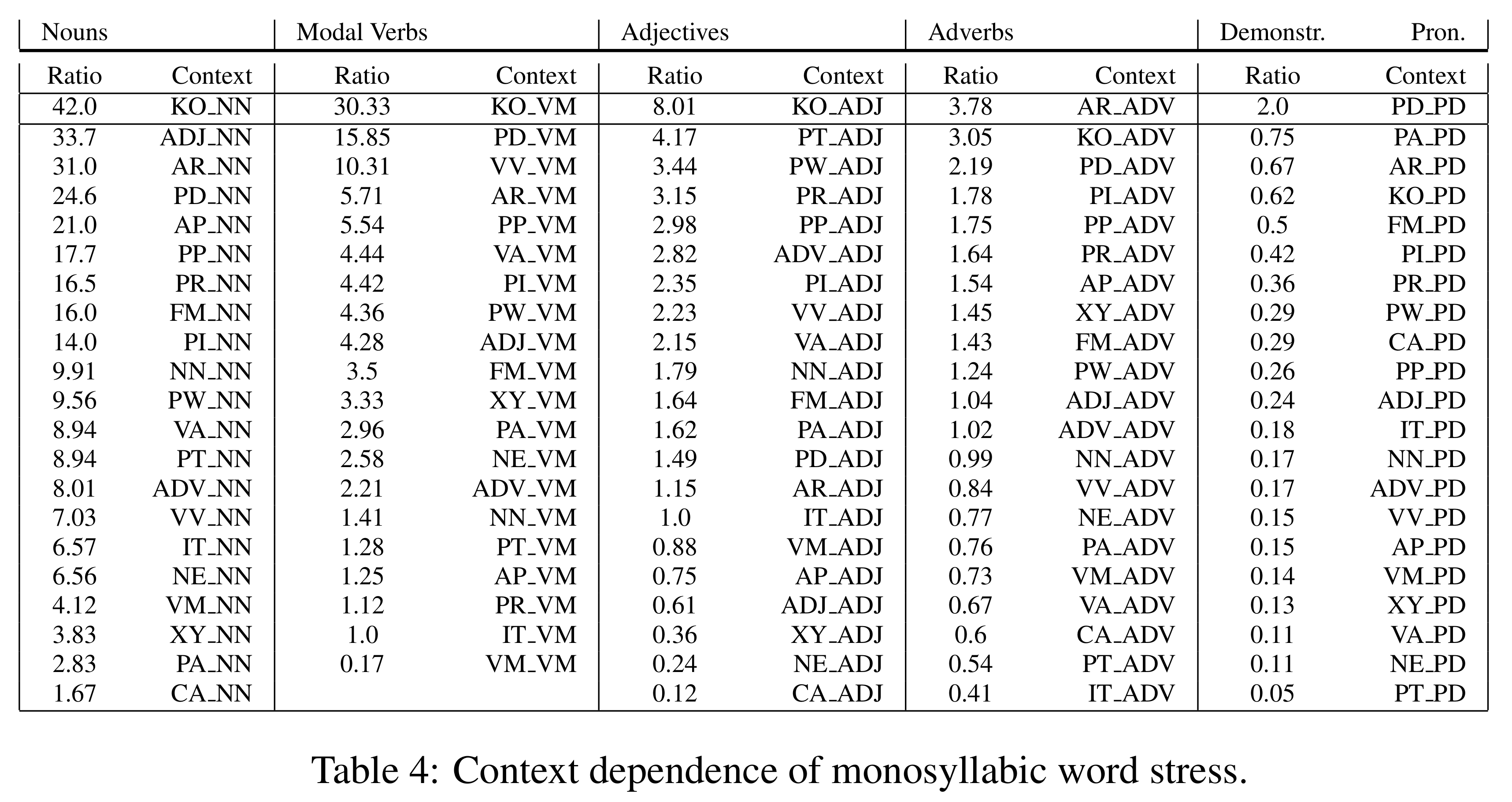
As words are heavily dependent on their context regarding their stress, we look at the immediate left and right context of POS tags, i.e., which POS tag occurs next to it. For brevity, we only show the left context. We retrieve the stress ratio for particular monosyllabic word classes dependent on their context. Context words can be multisyllabic. See Table 4 for an overview of nouns, modal verbs, adjectives, adverbs and demonstrative pronouns.
We can see that the hierarchy from Table 3 reiterates for contextual dependence. If a word is preceded by a conjunction (KO), then the likelihood of stress is higher. However, nouns never lose their prominence (r > 1), regardless of context. Most interestingly, adverbs, which are quite balanced, also show a balanced context dependence, while modal verbs are still mostly stressed, except when they are preceded by another modal verb. We acknowledge that this table can be problematic, such that some of these contexts seem atypical for particular word classes. Future research should investigate the frequency of particular contexts, and how significant they are. Lastly, the models may also introduce a systematic error that disproportionately affects certain POS classes.
2.3 Prose vs. Poetry Classification
To determine features that distinguish prose from poetic writing on a syntactic and rhythmic level, we perform classification with a regularized linear discriminant analysis that allows us to interpret feature loadings. Regularization is necessary, as many features are collinear, making the feature loadings not
interpretable (as collinear features will be important for both classes, without contributing to the classification).
For features, we use POS n-grams and rhythmic groups. POS n-grams are straightforward, where only subsequent POS tag sequences are considered. For rhythmic groups, we use the CRF trained ternary rhythm (TR) with caesuras, and split the sequences at caesuras. Consequently, a line ’0201:020’ yields the features ’0201’ and ’020’.
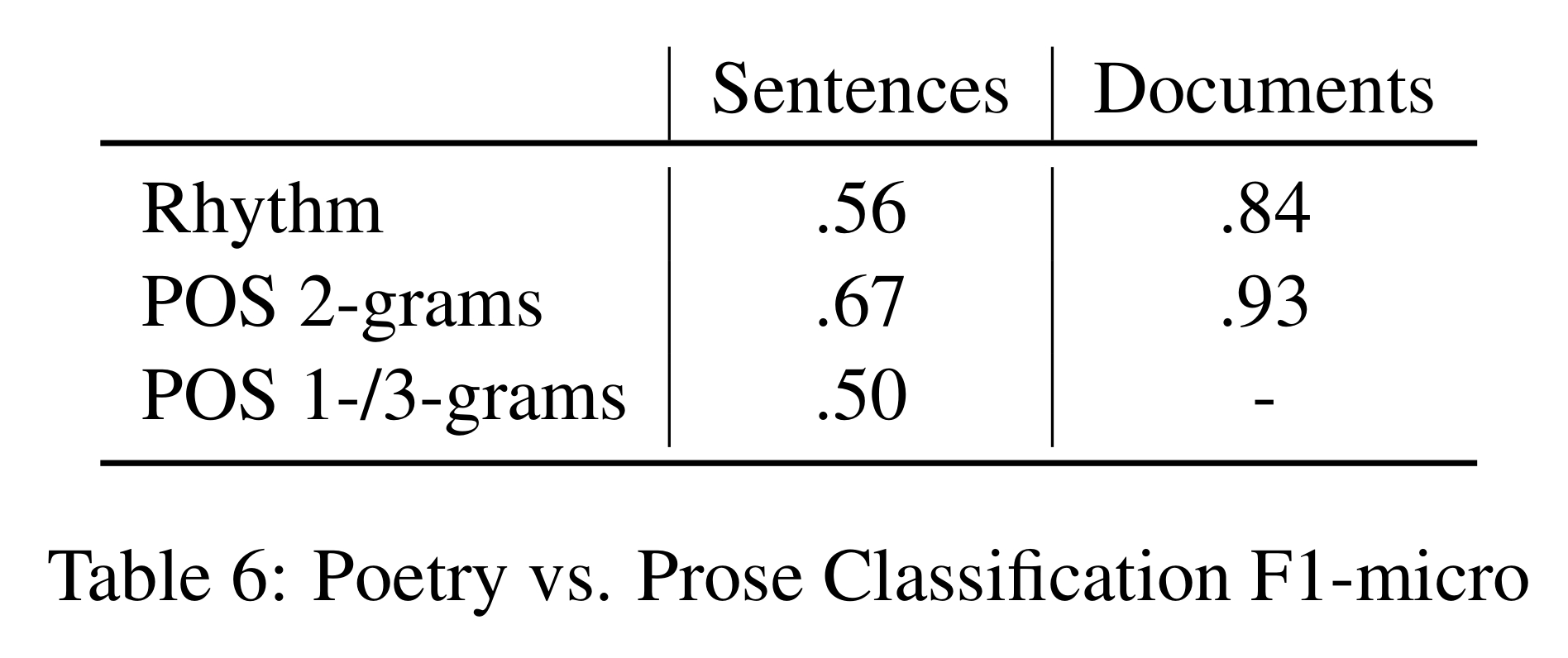
First, we tried to classify 100k sentences from poetry and prose (literature) respectively. We extracted
the sentences from DTA. For POS n-grams, using unigrams or trigrams did not beat the random 50% baseline. Training the classifier on bigrams achieves 67% F1. Classifying sentences based on rhythmic groups performed at 56%, marginally better than the random baseline.
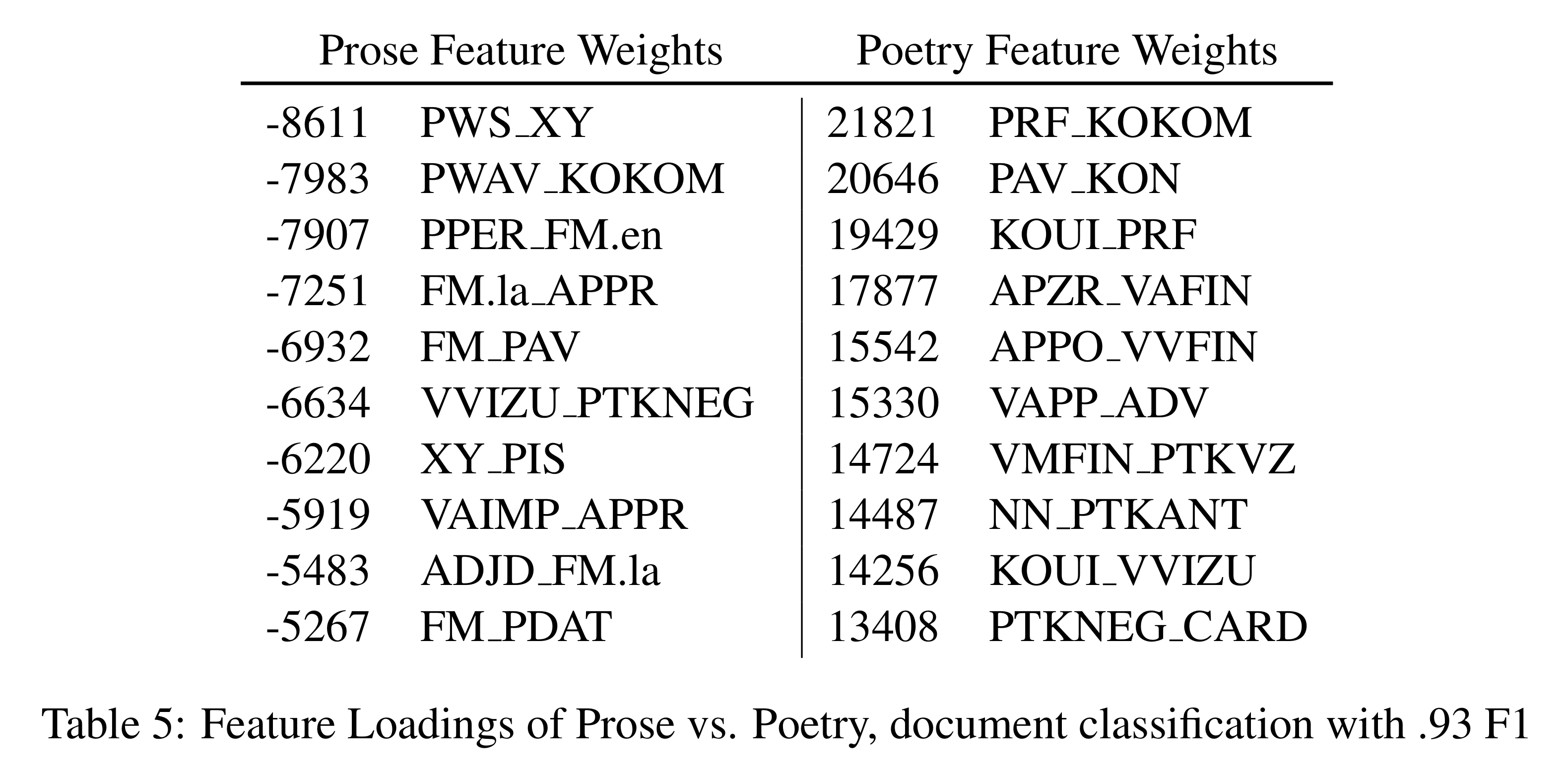
However, when we trained with POS bigrams on whole documents, F1 is around 93%, possibly because this classification relies on rare bigrams, such that sentence structure is often the same in poetry and prose, but when it differs, it differs strongly. See Table 5 for an overview of feature weights from this latter classification. Higher standing features are more important. It is notable that the positive features for prose include a significant amount of foreign language material (FM) and bigrams with a pronoun followed by ’not a word’ are most discriminative for this genre.
2.4 Versemeter vs. Enjambement
Our setup also allows us to get an impression of the interaction of enjambement with verse measures and also POS transitions between lines. Enjambement is an integral part of many poetic lines. It typically signifies incomplete syntax at the end of a line, such that the end of the line encourages a pause in speech, but the sentence, or clause, or phrase, or word is not yet finished. We use a simple way to operationalize enjambement, by assigning enj+ to lines that do not end on a punctuation mark, and enj- to lines that do. Beyond obvious cases (ART NN does not cross punctuation/clause boundaries), we could not identify clear preferences of enjambement for particular POS transistions.
We implement a set of regular expressions to detect a broad set of verse measures based on the syllable prediction of the meter CRF (here, we use I for stressed and o for unstressed syllables, while the symbol before ’?’ is optional and ’$’ is the end of the line). Unsurprisingly, we find that lines with fewer stressed syllables prefer enjambement more. However, for measures with six stressed syllables, the ’running measure’ hexameter (Ioo?Ioo?Ioo?Ioo?IooIo$) is more sympathetic with enjambement than any other measure with a probability of p(enj+) = .41, while the alexandrine (oIoIoIoIoIoIo?$) dislikes it, ranking
as most unlikely with p(enj+) = .16, compared to all other measures.
3 Conclusion
We have shown experiments on the intersection of syntax and speech rhythm, outlining stress hierarchies with and without context, questioning previous research. Lastly, we have shown that a classification of documents on POS bigrams shows clear distinctive features of poetry vs. prose, while classifying sentences is challenging. In the end, we also discussed first explorations regarding enjambement and its interaction with syntax and different verse forms.
References
Arto Anttila, Timothy Dozat, Daniel Galbraith, and Naomi Shapiro. 2018. Sentence stress in presidential speeches. Lingbuzz Preprints.
Derek Attridge. 2014. The rhythms of English poetry. Routledge.
Valentin Wagner Matthias Schlesewsky Blohm, Stefan and Winfried Menninghaus. 2018. Sentence judgments and the grammar of poetry: Linking linguistic structure and poetic effect. Poetics, 69:41–56.
Amitha Gopidi and Aniket Alam. 2019. Computational analysis of the historical changes in poetry and prose. In Proceedings of the 1st International Workshop on Computational Approaches to Historical Language Change, pages 14–22.
Erica Greene, Tugba Bodrumlu, and Kevin Knight. 2010. Automatic analysis of rhythmic poetry with applications to generation and translation. In Proceedings of the 2010 conference on empirical methods in natural language processing, pages 524–533.
Thomas Haider and Steffen Eger. 2019. Semantic change and emerging tropes in a large corpus of new high german poetry. In Proceedings of the 1st International Workshop on Computational Approaches to Historical Language Change, pages 216–222.
Willem JM Levelt. 1993. Speaking: From intention to articulation, volume 1. MIT press.
Winfried Menninghaus, Valentin Wagner, Eugen Wassiliwizky, Thomas Jacobsen, and Christine A Knoop. 2017. The emotional and aesthetic powers of parallelistic diction. Poetics, 63:47–59.
Winfried Menninghaus, Valentin Wagner, Christine A Knoop, and Mathias Scharinger. 2018. Poetic speech melody: A crucial link between music and language. PLoS One, 13(11):e0205980.
Ani Nenkova, Jason Brenier, Anubha Kothari, Sasha Calhoun, Laura Whitton, David Beaver, and Dan Jurafsky. 2007. To memorize or to predict: Prominence labeling in conversational speech.